Ontologie: studijní opora
| Site: | Moodle UK pro výuku 1 |
| Course: | Klasifikace a systémová analýza - AISPV1001 |
| Book: | Ontologie: studijní opora |
| Printed by: | Guest user |
| Date: | Monday, 7 July 2025, 10:49 PM |
Description
Zpracovala: Helena Kučerová
Table of contents
- 1. Úvod
- 2. Definice informatické ontologie
- 3. Historický přehled dosavadního vývoje informatických ontologií
- 4. Ontologie a znalostní systém
- 5. Oblasti užití informatických ontologií
- 6. Typologie informatických ontologií
- 7. Informatické ontologie a systémy organizace znalostí
- 8. Metody návrhu ontologie
- 9. Literatura
1. Úvod
Je-li řešení založené na ontologiích odpovědí, jak zní otázka?[1]
Mike Uschold, 2005
Slovo ontologie pochází z řečtiny a znamená „přemýšlení o bytí“, což je tradiční náplní filozofie. I když samotný termín ontologie se ve filozofii používá pro označení zkoumání otázek bytí až od 17. století[2], zkoumání toho, co je (řečeno slovy Martina Heideggera „jsoucí jakožto jsoucí“[3]), bylo pod nejrůznějšími názvy (metafyzika, první filosofie) součástí filozofie od jejích počátků. Za zakladatele ontologického bádání je považován Parmenides z Eleje (510–450 př. n. l.), který jako první v evropské filozofické tradici zpochybnil smyslový a empirický způsob zkoumání a byl zastáncem racionálního a logického poznávání světa.
Termín ontologie byl proto donedávna spojován především s filozofickou disciplínou zkoumající obecné principy bytí a s jejími výsledky. V poslední době se čím dál častěji objevuje i ve slovníku informatiků a informačních pracovníků včetně knihovníků, zejména v souvislosti s nástupem sémantického webu. Přes společné východisko, spočívající v zájmu o poznání skutečnosti, a obdobnou formu vyjádření v podobě pojmového / kategoriálního systému nabyl pojem ontologie v informatice svůj specifický význam.
Specifika informatických ontologií[4] oproti ontologiím filozofickým vyplývají z odlišně stanoveného cíle. Filozofické ontologie jsou vytvářeny pro „čisté“ poznání, informatické ontologie mají vždy specifický účel použití. Liší se i používané metody. Filozofické ontologie jsou výsledkem teoretického zkoumání v podobě abstraktních myšlenkových systémů, informatické ontologie jsou výsledkem inženýrského návrhu v podobě slovníků. Neusilují o řešení základních filozofických (ontologických) otázek, v tom jsou vždy závislé na některém filozofickém směru, tj. na některé z filozofických ontologií. John F. Sowa označuje filozofické ontologie (jež nazývá „vědecké ontologie“) za deskriptivní, informatické ontologie (jež nazývá „aplikované“ nebo „inženýrské“) mohou podle něj být deskriptivní i preskriptivní.[5]
Informatické ontologie jsou tedy inženýrské artefakty, které jsou navrhovány a implementovány se záměrem dosáhnout předem stanoveného cíle v nějaké konkrétní oblasti použití. Michael Grűninger a Jintae Lee zobecnili specifické oblasti využití informatických ontologií do tří základních okruhů: komunikace, počítačové odvozování, opakované využití a organizace znalostí[6] (blíže viz část 5).
Příklady ontologií:
[1] USCHOLD, Michael. An ontology research pipeline. In: Applied ontology. 2005, 1(1), s. 13. https://doi.org/10.3233/APO-2005-000003. ISSN 1570-5838 (print). ISSN 1875-8533 (online).
[2] Viz např. hesla „bytí“, „existence“, „jsoucno“, „metafyzika“, „ontický, ontologie, ontologický“ v jednom z filozofických slovníků: DUROZOI, Gérard, ROUSSEL, André. Filozofický slovník. Přeložili Jan Binder aj. 1. vyd. Praha: EWA, 1994, 352 s. ISBN 80-85764-07-5.
[3] HEIDEGGER, Martin. Co je metafyzika? Praha: Oikúmené 1993, s. 7.
[4] V některých anglicky psaných textech se používá pro odlišení typů ontologií místo přídavných jmen „filozofická“ a „informatická“ rozdílné psaní – filozofická disciplína se píše s počátečním velkým písmenem a je nepočitatelná, informatické ontologie jsou označené počitatelným podstatným jménem s počátečním malým písmenem. Tento způsob odlišení používá např. Nicola Guarino v GUARINO, Nicola, OBERLE, Daniel, STAAB, Steffen. What is an ontology? In: STAAB, Steffen, STUDER, Rudi, ed. Handbook on ontologies. 2nd ed. Dordrecht: Springer, 2009, s. 1-17. https://doi.org/10.1007/978-3-540-92673-3. ISBN 978-3-540-70999-2 (print). ISBN 978-3-540-92673-3 (online).
[5] SOWA, John F. Signs and reality. In: Applied ontology. 2015, 10(3-4), 273-284. https://doi.org/10.3233/AO-150159. ISSN 1570-5838 (print). ISSN 1875-8533 (online).
[6] GRÜNINGER, Michael, LEE, Jintae. Ontology applications and design. In: Communications of the ACM. February 2002, 45(2), s. 40. https://doi.org/10.1145/503124.503146. ISSN 0001-0782 (print). ISSN 1557-7317 (online).
2. Definice informatické ontologie
V dnes již značně rozsáhlé literatuře je možné se setkat s četnými pokusy o vytvoření definice informatické ontologie. Za reprezentativní lze považovat definici publikovanou v dokumentu specifikace požadavků na ontologický jazyk OWL, na jehož vytvoření se podílel Leo Obrst[7]. Definice vyjadřuje přístup konsorcia W3C k chápání obsahu pojmu ontologie:
„Ontologie definuje termíny používané k popisu a reprezentaci oblasti znalostí. Ontologie používají lidé, databáze a aplikace, potřebující sdílet informace o určité doméně … Ontologie zahrnují počítačem použitelné definice základních pojmů v doméně a vztahy mezi nimi … Kódují znalosti v doméně a také znalosti o těchto doménách. Tím umožňují, aby tyto poznatky byly opětovně použitelné.“[8]
Shrnutí pohledů na informatické ontologie z pozic oborů umělé inteligence a znalostního inženýrství nabízí monografie Ontological engineering (Ontologické inženýrství)[9]. V kapitole 1.2 autoři uvádějí 16 různých definic ontologie, přičemž konstatují, že jde pouze o výběr z velkého množství dalších definic, jež je možné najít v literatuře. V závěru vyvozují vlastní definici, v níž konstatují, že cílem ontologií je „zachytit konsenzuální znalosti obecným způsobem, aby mohly být znovu použity a sdíleny mezi softwarovými aplikacemi a skupinami lidí“[10].
Většina definic informatické ontologie je založena na výčtu typů entit, jež jsou považovány za ontologie. Prvním pokusem o vymezení ontologie klasickým aristotelským způsobem (odkaz na nadřazený pojem, uvedení specifických rozdílů) je definice Thomase Grubera z roku 1993[1]. Tato obecně přijímaná a často diskutovaná definice informatické ontologie lapidárně vystihuje její gnozeologický a sémiotický základ:
„Ontologie je explicitní specifikace konceptualizace.“[11]
V roce 1997 byla Gruberova definice doplněná Willemem Nico Borstem do následující formulace:
„Ontologie je formální explicitní specifikace sdílené konceptualizace skutečnosti“.[12]
Tato značně kompaktní formulace si zaslouží podrobnější komentář, v němž se ji pokusíme propojit s teoretickým konstruktem sémiotického trojúhelníku (podrobněji viz kapitola 5) a ukázat, jak odkazuje na všechny tři jeho vrcholy.
Lze konstatovat, že pojem „explicitní specifikace“ z definice ontologie odpovídá straně sémiotického trojúhelníku (viz obr. 3 Sémiotický trojúhelník) označené jako „vyjádření pojmu znakem“. Slovo „formální“ znamená, že specifikace pojmu je zakódovaná v nějakém formálním jazyce a tedy srozumitelná i počítačovým programům. Zbývá doplnit komentář k významu adjektiva „sdílená“ u slova konceptualizace. Konceptualizace spočívá v tvorbě kognitivního odrazu skutečnosti prostřednictvím pojmů. „Sdílená konceptualizace“ znamená, že konceptualizace je využívána ke komunikaci (komunikace v pojetí sdílení a opakovatelné použitelnosti významu), a že se tedy nejedná o individuální pojmovou reprezentaci skutečnosti, nýbrž o výsledek dohody o významu vyjadřovaných pojmů v nějaké širší komunitě, například v rámci vědního oboru. Potřeba sdílené konceptualizace ve formě pojmového schématu byla konstatována již v normě ISO/TR 9007 (viz kapitola 4). Příčinou nutnosti dohody o významu pojmů je nejen vztah typu více–více mezi pojmy a znaky, který se projevuje jako synonymie a homonymie, ale i obecně známý fenomén vágnosti a různá míra ustálenosti (stability) významu zejména v přirozeném jazyce. Sám termín ontologie se svými různými významy proměňujícími se v čase je toho konkrétním příkladem. Dohoda uživatelů ontologie o významu používaných znaků (slov, termínů) je proto jedním z nejvýznamnějších typů ontologických závazků.
Jako stavební bloky pro vlastní pracovní definici ontologie pro účely tohoto textu použijeme následující pojmy, jež představují pojmovou základnu systémové analýzy: třída, prvek, atribut a hodnota, doplněné o specifické ontologické pojmy axiom a ontologický závazek. Význam použitých pojmů vymezíme pomocí těchto výroků:
Konceptualizace
Reprezentace skutečnosti prostřednictvím pojmů - proces tvorby pojmového modelu domény.
Třída
Výsledek konceptualizace množiny objektů. Obsahem třídy jsou vlastnosti zahrnutých objektů, rozsahem třídy je množina objektů se stejnými vlastnostmi, tj. instancí.
Poznámka: Takto definovaná třída je ekvivalentní s pojmem.
Pojmový model
Model vymezené domény vytvořený pomocí pojmů a jejich vztahů - výstup procesu konceptualizace.
Instance
Objekt, jenž má vlastnosti třídy, naplněné konkrétními hodnotami (daty).
Vyjádření
Zastoupení (specifikace) pojmu znakem (tj. jeho označení).
Vztah
Typ vlastnosti, sdílený více entitami (tj. třídami nebo instancemi).
Axiom
Výrok, tvrzení o třídě, které se nedokazuje a jehož účelem je upřesnit její význam (sémantiku).[13]
Ontologické závazky
Předpoklady, pravidla a omezení uplatňovaná při konceptualizaci a konstrukci ontologie. Jejich funkce je obdobná jako funkce axiomů. Avšak zatímco axiomy se týkají jednotlivých tříd, ontologické závazky se vztahují k ontologii jako celku.
S pomocí výše uvedených pojmů a jejich definic zkonstruujeme klasickou aristotelskou definici informatické ontologie prostřednictvím nejbližšího nadřazeného pojmu a určením druhových specifik.
Nejbližším nadřazeným pojmem pro informatickou ontologii je pojmový model.
Účelem informatické ontologie je komunikace, opakované využití a organizace znalostí, popis skutečnosti pro počítačové zpracování a automatické odvozování znalostí (podrobněji viz kapitola 5).
Obsah (složení): Jádrem každé informatické ontologie jsou třídy a jejich vlastnosti.
Specifické vlastnosti informatické ontologie jsou vyjádřeny následujícími výroky:
Informatická ontologie je inženýrský artefakt navržený s předem stanoveným cílem.
Informatická ontologie je opakovaně použitelná.[14]
Informatická ontologie je sdílena nějakým rozsáhlejším okruhem uživatelů.[15]
Výběr tříd, jejich atributů a způsob strukturování informatické ontologie je založen na implicitně či explicitně stanovených ontologických závazcích.
Význam tříd v informatické ontologii je vymezen pomocí axiomů.
Pracovní definice pro účely této studijní opory:
Informatická ontologie je typ pojmového modelu vymezené domény. Jejím účelem je komunikace, opakované využití a organizace znalostí, popis skutečnosti pro počítačové zpracování a automatické odvozování znalostí. Má formu inženýrského artefaktu, navrženého s předem stanoveným cílem. Je opakovaně použitelná a sdílená nějakým rozsáhlejším okruhem uživatelů. Obsah informatické ontologie tvoří třídy a jejich vlastnosti. Význam tříd je vymezen pomocí axiomů. Výběr tříd, jejich atributů a způsob strukturování ontologie je založen na implicitně či explicitně stanovených ontologických závazcích.
[7] Viz OBRST, Leo. Ontologies for semanticaly interoperable systems. In: CIKM '03: Proceedings of the twelfth international conference on information and knowledge management, New Orleans, LA, USA - November 03-08, 2003. New York: ACM, 2003, s. 366. https://doi.org/10.1145/956863.956932. ISBN 1-58113-723-0.
[8] HEFLIN, Jeff, ed. OWL Web Ontology Language use cases and requirements [online]. W3C Recommendation 10 February 2004. Cambridge (MA): World-Wide Web Consortium, © 2004 [cit. 2024-05-09]. Dostupné z: https://www.w3.org/TR/webont-req/#onto-def.
[9] GÓMEZ-PÉREZ, Asunción, FERNÁNDEZ-LÓPEZ, Mariano, CORCHO, Oscar. Theoretical foundations of ontologies. In: Ontological engineering: with examples from the areas of knowledge management, e-commerce and the semantic web. 1st ed. London: Springer, 2004, s. 1-45. https://doi.org/10.1007/1-85233-840-7_1. ISBN 978-1-85233-551-9 (print). ISBN 978-1-85233-840-4 (online).
[10] Tamtéž, s. 8-9.
[11] „An ontology is an explicit specification of a conceptualization.“ GRUBER, Thomas R. A translation approach to portable ontology specification. In: Knowledge acquisition. June 1993, 5(2), 199. https://doi.org/10.1006/knac.1993.1008. ISSN 1042-8143.
[12] „Ontologies are defined as formal specification of a shared conceptualization.“ BORST, Willem Nico. Construction of engineering ontologies for knowledge sharing and reuse. Enschede: Centre for Telematics and Information technology, 1997, s. 12. CTIT Ph. D-thesis series, no. 97-14, ISSN 1381-3617. Dissertation (Ph.D.). Proefschrift Universiteit Twente, Enschede. ISBN 978-90-365-0988-6.
[13] Poznámka: Takovými axiomy jsou v naší „ontologii informatické ontologie“ pojmy „data“, „pojem“, „objekt“, „množina“, „vlastnost“.
[14] Tj. jedna ontologie může být využita pro více účelů.
[15] Tj. ontologie je výsledkem nějakého společenského konsenzu.
3. Historický přehled dosavadního vývoje informatických ontologií
Vzhledem k bohaté existující literatuře na toto téma se omezíme pouze na stručné shrnutí. Podrobnější přehled historie informatických ontologií lze najít například v příručce Handbook on ontologies[1] nebo v přehledovém textu Zdeňka Zdráhala[2].
Thomas Gruber (1959) v článku Ontologie v Encyklopedii databázových systémů[4] člení krátkou historii informatických ontologií na desetiletí. „Zakladatelská“ osmdesátá léta 20. století byla podle něj v režii oboru umělá inteligence. Umělá inteligence chápala ontologii jednak jako teorii modelovaného světa, tj. svého druhu aplikovanou filozofii, a jednak jako komponentu znalostních systémů, umožňující formální reprezentaci znalostí. Devadesátá léta 20. století přidala chápání ontologie jako nástroje sémantické interoperability a přinesla již výše zmíněnou definici ontologie jako explicitní specifikace konceptualizace. Tato definice odrážela přesun pozornosti směrem k nástrojům vyjádření pojmového obsahu ontologie, tj. k nejrůznějším typům slovníků, jež byly počátkem 21. století doplněny návrhem specifických jazyků (RDF, RDFS, OWL). První desetiletí 21. století je pak jednoznačně ve znamení nástupu sémantického webu, přičemž sémantiku mají zajišťovat právě ontologie. Příznačně to vystihuje název přehledového příspěvku Ontologie a WWW, který přednesl Vojtěch Svátek na konferenci Datakon 2002.[5]
V následujícím stručném historickém přehledu se budeme držet Gruberova členění, přičemž jeho třem vývojovým fázím ještě předřadíme "prehistorickou" vývojovou etapu.
[1] STAAB, Steffen, STUDER, Rudi, ed. Handbook on ontologies. 2nd ed. Dordrecht: Springer, 2009. xix, 811 s. International Handbooks on Information Systems. https://doi.org/10.1007/978-3-540-92673-3. ISBN 978-3-540-70999-2 (print). ISBN 978-3-540-92673-3 (online).
[2] ZDRÁHAL, Zdeněk. Ontologie: od filosofie k umělé inteligenci. In: Vladimír MAŘÍK, Olga ŠTĚPÁNKOVÁ, Jiří LAŽANSKÝ a kol. Umělá inteligence. 6. 1. vyd. Praha: Academia, 2013, kap. 1, s. 21-84. ISBN 978-80-200-2276-9.
[4] GRUBER, Thomas R. Ontology. In: Ling LIU, M. Tamer ÖZSU, ed. Encyclopedia of database systems. London: Springer, 2009, s. 1963-1965. https://doi.org/10.1007/978-0-387-39940-9_1318. ISBN 978-0-387-35544-3 (print). ISBN 978-0-387-39940-9 (online).
[5] SVÁTEK, Vojtěch. Ontologie a WWW. In: Dušan Chlapek, ed. DATAKON 2002: sborník databázové konference: Brno, Česká republika, 19.-22. října 2002. Brno: Masarykova univerzita, 2002, s. 27-55. ISBN 978-80-210-2958-3.
3.1. Prehistorie
Na úvod je vhodné zdůraznit, že přes poměrně krátkou historii má ontologické inženýrství k dispozici rozsáhlou poznatkovou bázi tvořenou výsledky tisíciletého filozofického zkoumání v podobě filozofických ontologií. Navíc mohou tvůrci informatických ontologií čerpat i z neméně dlouhé tradice organizace lidského poznání především v knihovnách, ať už byly příslušné činnosti nazývány třídění, klasifikace, indexace, katalogizace nebo pořádání. Tyto poznatky zobecňuje a teoreticky zkoumá informační věda. Následně jsou pak uplatněny v aplikační oblasti návrhu a implementace knihovních a informačních systémů, jejichž integrální součástí jsou i „knihovnické“ ontologie, označované jako systémy organizace znalostí (v rámci typologie představené v části 6 by bylo možné je zařadit do skupiny terminologických ontologií). Ty zůstávají zatím s výjimkou medicíny poněkud stranou pozornosti odborníků z oblasti informatiky. Jejich předností nebývá propracovaný systém vztahů a axiomů, ale bohatost lexikálního obsahu, který zase mnohdy chybí ontologiím vzniklým v laboratorních podmínkách. Na rozdíl od informatických ontologií, jež kladou důraz na opětovnou použitelnost znalostí, jsou „knihovnické“ ontologie zaměřeny na umožnění přístupu ke znalostem. K této linii tradice se hlásí i konsorcium OMG, jež v rámci standardu pro ontologický metamodel nabízí následující vymezení rozsahu pojmu informatické ontologie:
„Ontologie může co do expresivity sahat od taxonomie (znalosti strukturované hierarchicky nebo genericky stylem předek – potomek) k tezaurům (slova a synonyma), pojmovým modelům (se složitějším zachycením struktury znalostí) až k logické teorii (s velmi bohatými, složitými, konzistentními a smysluplnými znalostmi).”[3]
Knihovníkům a informačním pracovníkům může takový výčet znít velmi povědomě a potvrdit jim, že informatické ontologie nepřicházejí odkudsi z neznáma, ale naopak že představují aktuální etapu v rámci kontinuálního historického vývoje nástrojů organizace znalostí, tj. indexů, katalogů, klasifikačních schémat, taxonomií, číselníků, souborů autorit, heslářů ad.
Lze tedy konstatovat, že při tvorbě informatických ontologií se po letech relativně izolovaného vývoje naskýtá možnost synergie nahromaděných zkušeností filozofů, knihovníků a informatiků. Zkušenosti filozofů a knihovníků jsou nesporně rozsáhlejší a dlouhodobější. Informatici své zkušenosti shromažďují sice nepoměrně kratší dobu cca od 40. let 20. století, nicméně s tou výhodou, že se ve své praxi mohou opřít o principy matematiky, logiky a systémové vědy a o nejnovější informační technologie.
[3] Object Management Group. Ontology definition metamodel (ODM) [online]. Version 1.1. Needham (MA, USA): Object Management Group, September 2014 [cit. 2025-04-05], s. 31. OMG Document Number: formal/2014-09-02. Dostupné z: https://www.omg.org/spec/ODM/.
3.2. Ontologie a umělá inteligence
Jak bylo uvedeno, v 80. letech 20. století začali termín ontologie systematicky používat vědci z oboru umělá inteligence. V roce 1980 použil termín ontologie jeden ze zakladatelů oboru John McCarthy (1927–2011) jako název pro formalizaci kontextu, v němž probíhá nemonotónní odvozování.[6] Významným příspěvkem ke koncepci ontologií se stal obor reprezentace znalostí. Další z průkopníků umělé inteligence Allen Newell (1927–1992) definuje reprezentaci znalostí jako proces, který zajišťuje, aby znalost byla dostupná tomu, kdo ji má používat.[7] Zdeněk Zdráhal doplňuje, že proces reprezentace spočívá ve vyjádření znalosti nějakým přirozeným nebo umělým jazykem.[8] Toto široké pojetí se často zužuje na řešení problému reprezentace lidských znalostí strojům, typicky počítačovým programům. Randall Davis se spoluautory pojmenovali následujících pět rolí reprezentace znalostí, jež se do značné míry kryjí se současným pohledem na oblasti užití informatických ontologií (viz část 5). 1. Náhražka (surogát) věci samé, umožňující určit důsledky přemýšlením o ní, 2. množina ontologických závazků, 3. fragmentární teorie inteligentního usuzování s povolenými a nepovolenými možnostmi odvozování, 4. médium pro efektivní počítačové zpracování, 5. médium pro komunikaci.[9]
[6] McCARTHY, John. Circumscription: a form of non-monotonic reasoning. In: Artificial intelligence. April 1980, 13(1-2), s. 31. https://doi.org/10.1016/0004-3702(80)90011-9. ISSN 0004-3702.
[7] NEWELL, Allen. The knowledge level. In: Artificial intelligence. January 1982, 18(1), 114. https://doi.org/10.1016/0004-3702(82)90012-1. ISSN 0004-3702.
[8] ZDRÁHAL, Zdeněk. Reprezentace znalostí. In: Vladimír MAŘÍK, Jiří LAŽANSKÝ, Olga ŠTĚPÁNKOVÁ a kol. Umělá inteligence. 1. 1. vyd. Praha: Academia, 1993, kap. 4, s. 99-122. ISBN 978-80-200-0496-3.
[9] DAVIS, Randall, SHROBE, Howard, SZOLOVITS, Peter. What is a knowledge representation? In: AI magazine. Spring 1993, 14(1), 17-33. https://doi.org/10.1609/aimag.v14i1.1029. ISSN 0738-4602.
3.3. Ontologie a informační systémy
Dalším myšlenkovým proudem, který přispěl k formování teoretické základny informatických ontologií, je tvorba pojmových modelů informačních systémů. Už v 60. letech 20. století uvedl ontologickou problematiku do oblasti informatiky matematik a informatik George H. Mealy (1927–2010), autor koncepce tzv. Mealyho stroje – konečného automatu s výstupem. V článku Jiný pohled na data[10] z roku 1967 Mealy zformuloval náčrt obecné teorie dat použitelné pro tvorbu programovacích jazyků. Vychází z filozofického základu a koncipuje významné stavební prvky ontologického pohledu na data. Není bez zajímavosti, že Mealy vedl disertační práci Petera Pin-Shan Chena (1947), autora pojmového ER (z angl. entity-relationship, tj. entita–vztah) modelu[11], který se spolu s relačním modelem dat Edgara F. Codda (1923–2003)[12] stal základem koncepce databázových informačních systémů v druhé polovině 20. století.
V roce 1982 Allen Newell ke dvěma obecně akceptovaným úrovním reprezentace počítačových systémů, tj. k úrovni zařízení (komponenty, logické obvody…) a k úrovni symbolické (programy), doplnil úroveň znalostí[13]. Úroveň zařízení a symbolická úroveň obsahují znalosti o vnitřní struktuře systému, jež odrážejí jeho fyzickou stránku. Znalostní úroveň podle Newella pohlíží na systém jako na černou skříňku a zajímá se o jeho fungování vzhledem k okolí, o poskytované služby a řešené problémy. Na toto pojetí navázali v roce 1987 tvůrci technické zprávy ISO/TR 9007 Pojmy a terminologie pro pojmové schéma a informační základnu, v níž je definována tříúrovňová architektura dat v informačním systému: pojmové schéma, vnější schéma a vnitřní schéma (podrobněji viz část 4). Vnitřní a vnější schéma se zaměřují na znalosti o formě obsažených informací. Pojmové schéma zachycuje znalosti o obsahu informací v informačním systému, čímž odpovídá zhruba Newellově znalostní úrovni.
Aktuální implementací principu znalostního/pojmového modelu v návrhu informačních systémů a aplikací je od roku 2001 MDA – Model driven architecture (Architektura řízená modelem)[14]. Tato specifikace konsorcia OMG definuje koncepci architektury softwarových aplikací, jež zahrnuje tři typy postupně konkretizovaných modelů, reprezentujících úrovně znalostí o informačních systémech a aplikacích. Na nejobecnější úrovni je model nezávislý na počítačovém zpracování (CIM – Computation Independent Model), zachycující znalosti o oblasti použití systému, například model podnikových procesů. Další úrovní je pojmový model nezávislý na platformě (PIM – Platform Independent Model), v němž jsou obsaženy znalosti o pojmech reprezentovaných systémem. Tento model odpovídá pojmovému schématu podle ISO/TR 9007. Model pro specifickou platformu (PSM – Platform Specific Model) odpovídá vnitřnímu schématu informačního systému podle ISO/TR 9007.
Důležitý význam má i další specifikace konsorcia OMG, věnovaná metamodelu pro návrh ontologií: ODM – Ontology Definition Metamodel (Metamodel definice ontologie).[15] První verze standardu byla publikována v roce 2009 a v roce 2014 byla vydána aktualizovaná verze 1.1. Cílem je sloučit „softwarově“ zaměřený koncept MDA s technologiemi sémantického webu a vytvořit zobecněný model struktury informatické ontologie. ODM zahrnuje i specifikace vzájemného mapování metamodelů v různých jazycích a jejich mapování do UML a ER modelů.
[10] MEALY, George H. Another look at data. In: Proceedings of the Fall Joint Computer Conference (AFIPS Fall '67), November 14-16, 1967. New York: ACM, 1967, 525-534. https://doi.org/10.1145/1465611.1465682.
[11] CHEN, Peter Pin-Shan. The entity-relationship model – toward a unified view of data. In: ACM Transactions on Database Systems. March 1976, 1(1), 9-36. https://doi.org/10.1145/320434.320440. ISSN 0362-5915 (print). ISSN 1557-4644 (online).
[12] CODD, Edgar F. A relational model of data for large shared data banks. In: Communications of the ACM. June 1970, 13(6), 377-387. https://doi.org/10.1145/362384.362685. ISSN 0001-0782 (print). ISSN 1557-7317 (online).
[13] NEWELL, Allen. The knowledge level. In: Artificial intelligence. January 1982, 18(1), 87-127. https://doi.org/10.1016/0004-3702(82)90012-1. ISSN 0004-3702.
[14] Object Management Group. MDA guide. Revision 2.0 [online]. Needham (MA, USA): Object Management Group, June 2014 [cit. 2024-05-09]. 15 s. Document Number: ormsc/2014-06-01. Dostupné z: http://www.omg.org/cgi-bin/doc?ormsc/14-06-01.
[15] Object Management Group. Ontology definition metamodel (ODM) [online]. Version 1.1. Needham (MA, USA): Object Management Group, September 2014 [cit. 2024-05-09]. 348 s. OMG Document Number: formal/2014-09-02. Dostupné z: http://www.omg.org/spec/ODM/.
3.4. Ontologie a sémantický web
S nástupem sémantického webu a propojených dat v první a druhé dekádě 21. století přibyla nová oblast použití ontologií. Dosavadní představa ontologie jako pojmového modelu pro (navrhovaný) znalostní systém je doplněna o pojetí ontologie jako nástroje sémantické interoperability v spontánně vznikající a neustále se měnící síti propojených dat. V současné etapě vývoje ontologií zaměřené na aplikace sémantického webu hraje důležitou standardizační roli konsorcium W3C. Jeho nejvýznamnějším příspěvkem jsou jazyky pro návrh a zápis ontologie: RDF (Resource description framework, 1. verze byla publikována v roce 1999), RDFS (RDF Schema, 1. verze publikována v roce 2014), OWL (Web ontology language, 1. verze publikována v roce 2004) a SKOS (Simple knowledge organization system, 1. verze publikována v roce 2009).
4. Ontologie a znalostní systém
Tradičním kontextem informatických ontologií je informační, resp. znalostní systém. Na nejobecnější úrovni lze dokonce konstatovat, že informační systémy a informatické ontologie vykazují shodné vlastnosti. Název napovídá, že obsah znalostního systému tvoří znalosti. Výchozím pojmem většiny definic informatické ontologie je rovněž znalost a možnosti jejího opětovného použití. Shoda panuje i v technologii: společnou bází informačních i znalostních systémů a informatických ontologií jsou informační technologie, techniky softwarového a znalostního inženýrství a umělé inteligence. V této kapitole se proto zaměříme na specifikaci vzájemného vztahu informačních systémů a ontologií. Využijeme k tomu pojmový model informačního systému definovaný v technické zprávě ISO/TR 9007 Pojmy a terminologie pro pojmové schéma a informační základnu[1], která byla zmíněna v předchozí kapitole. Tento model budeme konkretizovat, aby vystihoval specifika znalostních systémů, a do takto konkretizovaného modelu začleníme pojem informatické ontologie.
Z hlediska funkce lze za informační systém považovat jakýkoli systém umožňující komunikaci a transformaci informací a/nebo znalostí – časově, prostorově i co do formy tak, aby byly lépe využity než v původním stavu. Jde tedy o systém, který přidává hodnotu ke zpracovávaným či komunikovaným informacím a/nebo znalostem za účelem odstranění informačních bariér. Typickými úlohami řešenými informačními systémy jsou kromě saturování potřeby informací a/nebo znalostí (pro poznání, pro rozhodování, pro realizaci určité činnosti) problémy složitosti, opětovné použitelnosti, automatizace, komunikace a problémy bezpečnosti, spolehlivosti a minimalizace rizik.
Informační systém představuje dialektickou jednotu statického a dynamického. Má jak svou stránku pasivní – je artefaktem modelujícím svět (modelem, reprezentací, odrazem reality) prostřednictvím informací a/nebo znalostí, tak stránku aktivní – je procesem působícím na svět, procesy, jež realizuje s informacemi, ovlivňují realitu. Yair Wand a Ron Weber nabízejí v souladu s tímto pojetím dva pohledy na informační systém:
„1. Reprezentace systému reálného světa, tak jak jej někdo vnímá, prostřednictvím artefaktů, vytvořená k tomu, aby plnila funkce zpracování informací.
2. Mechanismus zachycující stavy systému reálného světa, který má modelovat.“[2]
Gove Allen a Salvatore March navrhují upřesnit formulaci druhého pohledu na „mechanismus zpracovávající události”[3], tak aby byla explicitně vyjádřena dynamická stránka informačního systému.
Technická zpráva ISO/TR 9007 definuje jak statické, tak dynamické komponenty informačního systému. Klíčovými statickými komponentami informačního systému jsou informační základna (angl. information base) a pojmové schéma[4] (angl. conceptual schema) a dynamickou složku představuje informační procesor (angl. information processor). Obrázek 1 znázorňuje obecnou strukturu informačního systému ve formě diagramu tříd v jazyce UML.

Obr. 1 Informační systém podle ISO/TR 9007
Informační procesor je v ISO/TR 9007 specifikován jako „mechanismus, který podle zadaného příkazu vykonává požadovanou činnost v pojmovém schématu a informační základně“[5]. V převážné většině typů informačních systémů plní tuto funkci software.
Na obrázku 1 je znázorněno, že základním stavebním prvkem statických komponent informačního systému jsou výroky (věty), jež tvoří základ jak pro informační základnu, tak pro pojmové schéma.
Informační základnu tvoří podle ISO/TR 9007 „soubor vět konzistentních jak navzájem, tak i s pojmovým schématem, vyjadřující výroky odlišné od nutných výroků, které platí pro určitý svět entit“[6]. V konkrétních typech informačních systémů jsou pro informační základnu používány specifické termíny – informační základna transakčních databázových systémů se označuje jako databáze[7] (angl. data base), informační základnu znalostních systémů tvoří znalostní báze (angl. knowledge base). V současné době se výroky v informační základně často označují jako instance.
Technická zpráva ISO/TR 9007 věnuje pozornost především pojmovému schématu. V souvislosti s ním zavádí významný pojem „univerzum diskurzu“, tj. obor rozpravy či úvah[8], jímž se jednoznačně vymezuje sémantický prostor v rámci nějaké úlohy (například při pojmovém modelování) či zkoumání v konkrétních vědních disciplínách. Norma vymezuje univerzum diskurzu následovně: „Jsou to všechny entity, o které se zajímáme, které byly, jsou nebo mohou být.“[9]. Pojmové schéma je v normě definováno jako „ucelený soubor vět vyjadřujících nutné výroky, které platí pro univerzum diskursu“[10]. Na rozdíl od instancí v informační základně jsou jednotky pojmového schématu obvykle označovány jako třídy. Cílem pojmového schématu je jednoznačně definovat význam dat v informační základně pro různé uživatele. Význam jednoznačného definování se v normě zdůvodňuje následovně:
„Nejdůležitější charakteristikou prostředí datových základen je, že společná data jsou sdílena mezi mnoha uživateli jednoho systému. Sdílením společných dat zakládají tito uživatelé prostřednictvím systému mezi sebou dialog. Je zřejmé, že pro užitečnost a spolehlivost této komunikace musí existovat jednotné chápání informací prezentovaných daty. Protože se může stát, že dva uživatelé se nikdy nesetkají, musí být společné chápání řízeno něčím, co stojí mimo ně. Toto společné chápání musí být zaznamenané a v pravidlech k založení dialogu musí být ustanovena potřebná, předem stanovená gramatická pravidla.“[11]
Na obrázku 2 je základní schéma informačního systému doplněno o entity významné pro znalostní systém. Znalostní systém je znázorněn pomocí symbolu generalizace jako specifický typ informačního systému, což vyjadřuje, že jeho charakteristika je odvozena z obecných vlastností informačního systému, týkajících se jeho obsahu, funkce a klíčových komponent. Tyto „zděděné“ obecné vlastnosti jsou pak v rámci znalostního systému specifikovány a doplněny o další důležité charakteristiky.
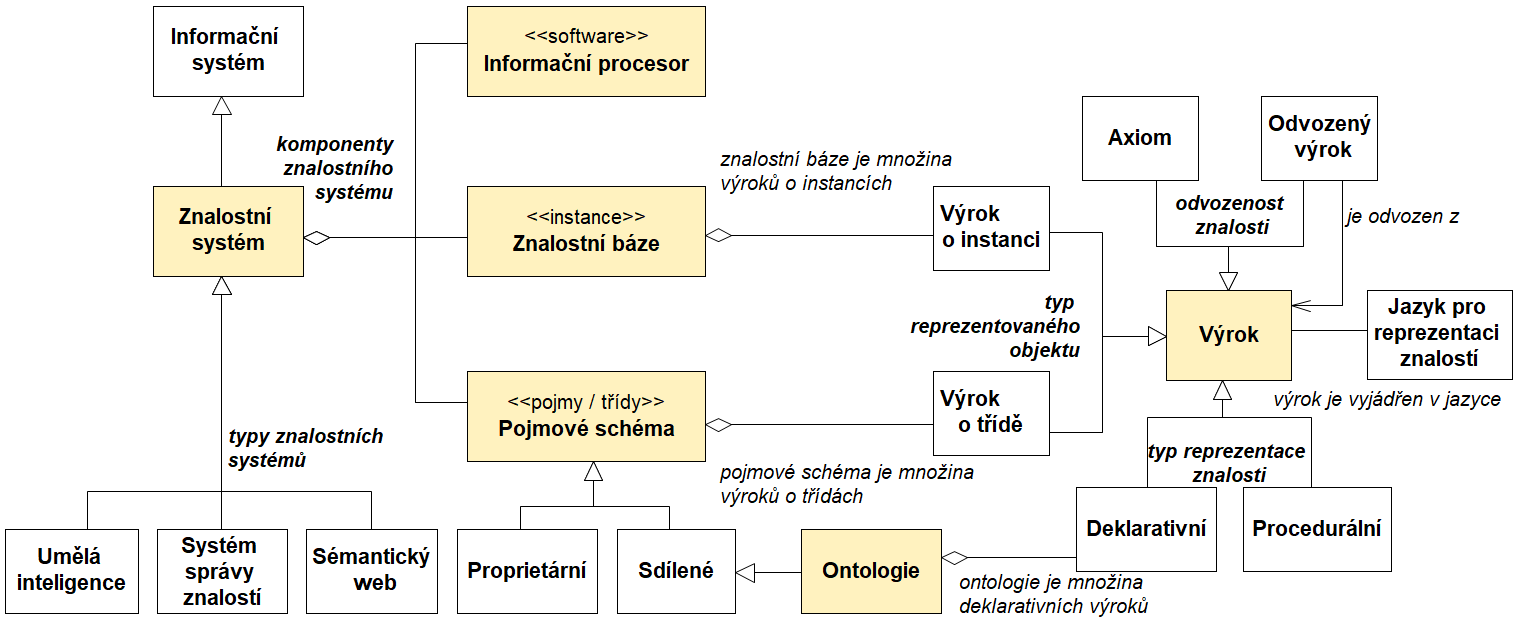
Obr. 2 Znalostní systém s ontologií podle ISO/TR 9007
K chápání obsahu a funkce znalostního systému se zpravidla jinak přistupuje v oblasti umělé inteligence, a jinak v pragmatičtěji orientované oblasti znalostního managementu. Vyjdeme z typologie Joerga Evermanna, který rozlišuje dvě kategorie znalostních systémů[12]: systémy založené na znalostech a systémy správy znalostí.
Systémy založené na znalostech (angl. knowledge-based systems) používají explicitní znalosti k automatickému usuzování a k odvozování nových znalostí. Obsažené znalosti jsou reprezentované formálními jazyky založenými na logice. Jejich uživatelem je software, například inteligentní agent. Tato kategorie je ve schématu na obrázku 2 označena v souladu s jejími teoretickými principy jako „umělá inteligence“.
Systémy správy znalostí (angl. knowledge management systems) spravují explicitní znalosti pro účely jejich sdílení mezi lidskými aktéry. Obvykle se vymezují v kontextu nějaké organizace. Organizace jsou potom považovány za místo zpracování a uchovávání znalostí a vytváření podmínek pro vznik nových znalostí (inovace). Tyto systémy obsahují zpravidla znalosti reprezentované přirozeným jazykem, předpokládanými uživateli jsou lidé.
Třetí kategorií znalostních systémů znázorněnou na obrázku 2 je sémantický web, do jehož prostředí se aktuálně přesouvají mnohé znalostní systémy z původních oblastí použití. Znalosti jsou obsaženy v distribuovaných webových zdrojích a jejich typickou vlastností je diverzita. Typickou strukturu tvoří grafové struktury propojených dat. Webové zdroje mohou obsahovat jak rigorózně formalizované znalosti, tak znalosti vyjádřené neformálně. Co do struktury aktuálně převažují grafové struktury propojených dat.
Specifika znalostních systémů v rámci množiny informačních systémů se týkají všech komponent popsaných výše: informační základny, pojmového schématu i informačního procesoru.
Informační základna znalostního systému se obvykle označuje jako znalostní báze nebo jako znalostní graf.
Informační procesor znalostního systému umožňuje realizovat takové operace s daty, při nichž dochází ke změně a/nebo k tvorbě nového obsahu či rozhodovací procedury díky netriviálnímu odvozování nových znalostí ze znalostí zachycených ve znalostní bázi. To je umožněno tím, že na rozdíl od transakčních informačních systémů je softwaru, který realizuje operace s daty, srozumitelná nejen syntax, ale díky ontologii i sémantika znalostní báze.
Stejně jako v informačním systému je i ve znalostním systému základním stavebním prvkem výrok coby konkrétní forma znalosti zaznamenané ve znalostním systému. Aby byl obsah pojmového schématu a informační základny komunikovatelný, je zapotřebí jej vyjádřit nějakým jazykem. Tuto komponentu znalostního systému znázorňuje na obrázku 2 třída „Jazyk pro reprezentaci znalostí“.
Na obrázku 2 je znázorněna typologie výroků ve znalostním systému. K již uvedené typologii výroků v informačním systému, jež člení výroky podle typu reprezentovaného objektu na výroky o instancích a na výroky o třídách, jsou doplněny další dvě typologie. Podle odvozenosti znalosti se výroky člení na axiomatické a odvozené. Z hlediska obsahu, přesněji řečeno podle způsobu reprezentace znalostí, se výroky ve znalostním systému obvykle člení na deklarativní a procedurální. „Inteligence“ deklarativních výroků je obsažena v datech a jejich strukturách, „inteligence“ výroků procedurálních je obsažena v procesech/programech, pravidlech, heuristikách. K těmto dvěma typům inteligence by bylo možné ještě připojit další typ, který přináší koncept propojených dat v sémantickém webu – „inteligence“ je obsažena v sémantickém propojení dat, tj. v jejich vztazích.
Členění výroků na procedurální a deklarativní je odvozeno z termínů používaných pro odlišení dvou typů znalostí – procedurálních a deklarativních. Procedurální (operační) znalost umožňuje úspěšnou realizaci nějaké akce nebo činnosti, deklarativní (konceptuální) znalost má formu tvrzení či výroku o poznané entitě, u nějž má smysl určovat, zda je pravdivý. Jejich specifika se projevují jak v modelování, tak ve způsobu reprezentace a v mechanismech odvozování a usuzování. Modely procedurálních znalostí se zaměřují na metody a algoritmy řešení úloh či problémů ve formě pravidel využívaných k diagnostice a rozhodování komplikovaných problémů, typickou aktuální aplikací jsou webové služby a mobilní aplikace. Modely deklarativních znalostí směřují k umožnění přístupu ke znalostem (vyhledávání a objevování) a ke generování nových znalostí. Jejich převažující formou jsou informatické ontologie. Typickou aktuální aplikací jsou znalostní grafy. Zatímco pro rané stadium výzkumu a aplikací v oblasti umělé inteligence byla typická snaha o modelování, reprezentaci a odvozování procedurálních znalostí, ontologie obrátily pozornost odborníků na znalosti deklarativní.
Uvedené členění navozuje dojem, že je vždy možné prohlásit znalost buď za deklarativní, nebo za procedurální, ve skutečnosti se však běžně vyskytují znalosti, vykazující rysy obou skupin. Tento názor zastává Allen Newell, který upozorňuje na obtíže s vyjádřením a zachycením znalosti a zároveň na její dialektickou povahu:
„Znalost není reprezentovatelná strukturou na úrovni symbolů. Vyžaduje jak struktury, tak procesy. Znalost zůstává navždy abstraktní a nikdy ji nelze mít skutečně k dispozici (pod kontrolou)“[13].
Příkladem snahy o propojení deklarativních a procedurálních znalostí je současné objektově orientované paradigma softwarových aplikací. V diagramech tříd, které se používají k jejich modelování, se v jedné třídě současně objevují jak deklarativní znalosti v podobě atributů, tak procedurální znalosti v podobě metod. V abstraktním pohledu von Neumannovy architektury počítačů dokonce deklarativní a procedurální znalosti splývají – jak data, tak programy jsou uloženy v paměti ve stejném formátu.
Kromě sdílení různými uživateli připadá v úvahu i sdílení pojmového schématu více systémy. Z tohoto pohledu se pojmová schémata znalostních systémů člení na proprietární nebo sdílená. Proprietární pojmové schéma je vytvořeno speciálně pro jeden konkrétní systém, sdílené schéma je použitelné pro více systémů. Nejvýznamnějším typem sdílených pojmových schémat jsou informatické ontologie.[14] Jak bylo uvedeno, obvykle mají formu množiny deklarativních výroků o třídách objektů v dané oblasti zájmu. Díky své deklarativní povaze vykazují vyšší míru nezávislosti na programech, jež s nimi mohou pracovat, a tím i vyšší míru opětovné použitelnosti.
Informační základnu znalostního systému představuje znalostní báze, tvořená množinou výroků reprezentujících tvrzení o univerzu diskurzu, vyjádřených v jazyce pro reprezentaci znalostí. Na rozdíl od informačních základen transakčních informačních systémů se znalostní báze vnímá jako těsněji spjatá s pojmovým schématem, v literatuře se lze setkat i s tím, že termínem znalostní báze je označován komplex pojmového schématu a instancí (tj. dat ve znalostní bázi). Existují i ontologie, v nichž jsou kromě výroků o třídách obsaženy i výroky o instancích.
Znalostní báze je klíčovou komponentou všech tří výše uvedených typů znalostních systémů, často ovšem s odlišnými funkcemi. V systémech umělé inteligence se báze znalostí využívá jako podmínka, východisko pro procedury či aktivity – například pro plánování, rozhodování, diagnostiku, rozpoznávání ad. Systémy správy znalostí typicky chápou bázi znalostí jako výsledný produkt – zdroj poznání umožňující opětovné použití a vyhledávání a jako podmínku, východisko pro komunikaci. Znalostní bázi sémantického webu tvoří distribuované webové zdroje opatřené sémantickými metadaty. Na rozdíl od proprietárních systémů umělé inteligence a systémů správy znalostí disponuje sémantický web standardizovaným jazykem i softwarem. Jazykem pro reprezentaci znalostí v sémantickém webu je RDF[15] (podrobněji viz kapitola RDF studijní opory ke strukturám informačních zdrojů). Funkci informačního procesoru plní protokol HTTP.
[1] Následující citace uvádíme podle českého překladu normy: ČSN ISO/TR 9007 (97 9702). Systémy zpracování informací: Pojmy a terminologie pro pojmové schéma a informační základnu. Praha: Český normalizační institut, 1996. 131 s.
[2] WAND, Yair, WEBER, Ron. Toward a theory of the deep structure of information systems. In: Janice I. DeGROSS, Maryam ALAVI, Hans J. OPPELLAND, ed. Proceedings of the Eleventh International Conference on Information Systems, December 16-19, 1990, Copenhagen, Denmark. Baltimore: ACM Press, © 1990, s. 62.
[3] ALLEN, Gove N., MARCH, Salvatore T. A critical assessment of the Bunge-Wand-Weber ontology for conceptual modeling [online]. In: 16th Annual workshop on information technologies and systems (WITS), Milwaukee, WI, Dec. 9-10 2006. https://doi.org/10.2139/ssrn.951803.
[4] Poznámka: V dalším textu používáme termín pojmový model, v této pasáži je ponechána původní terminologie použitá v českém překladu normy.
[5] ČSN ISO/TR 9007. Systémy zpracování informací: Pojmy a terminologie pro pojmové schéma a informační základnu. Praha: Český normalizační institut, 1996, s. 49.
[6] Tamtéž, s. 50.
[7] Poznámka: V českém překladu normy se používá termín „datová základna“.
[8] „Diskurz je projev racionálního myšlení v podobě souvislé řady úsudků, jež se opírají o dílčí operace a pojmy.“ DUROZOI, Gérard, ROUSSEL, André. Filozofický slovník. Přeložili Jan Binder aj. 1. vyd. Praha: EWA, 1994, s. 61. ISBN 80-85764-07-5.
[9] ČSN ISO/TR 9007. Systémy zpracování informací: Pojmy a terminologie pro pojmové schéma a informační základnu. Praha: Český normalizační institut, 1996, s. 16.
[10] Tamtéž, s. 50.
[11] Tamtéž, s. 8.
[12] EVERMANN, Joerg. Towards a cognitive foundation for knowledge representation. In: Information systems journal. April 2005, 15(2), 147-178. https://doi.org/10.1111/j.1365-2575.2005.00193.x. ISSN 1350-1917 (print). ISSN 1365-2575 (online).
[13] NEWELL, Allen. The knowledge level. In: Artificial intelligence. January 1982, 18(1), s. 125. https://doi.org/10.1016/0004-3702(82)90012-1. ISSN 0004-3702.
[14] Vzájemný vztah pojmových modelů a informatických ontologií je rozpracován v: WEBER, Ron. Conceptual modeling and ontology: possibilities and pitfalls. In: Journal of database management. July-September 2003, 14(3), 1-20. https://doi.org/10.4018/jdm.2003070101. ISSN 1063-8016.
[15] Resource description framework (RDF) [online]. W3C RDF Working Group, last modified 2018-01-16 [cit. 2024-05-09]. Dostupné z: https://www.w3.org/RDF/.
5. Oblasti užití informatických ontologií
V úvodu tohoto textu bylo uvedeno, že za hlavní oblasti využití informatických ontologií lze na obecné úrovni považovat komunikaci znalostí, počítačové odvozování znalostí a opakované využití a organizaci znalostí. V následujícím souhrnu doplníme k této trojici i oblasti užití, formulované Zdeňkem Zdráhalem[1], a v teoretické rovině se je pokusíme propojit s odpovídajícími sémiotickými pojmy.
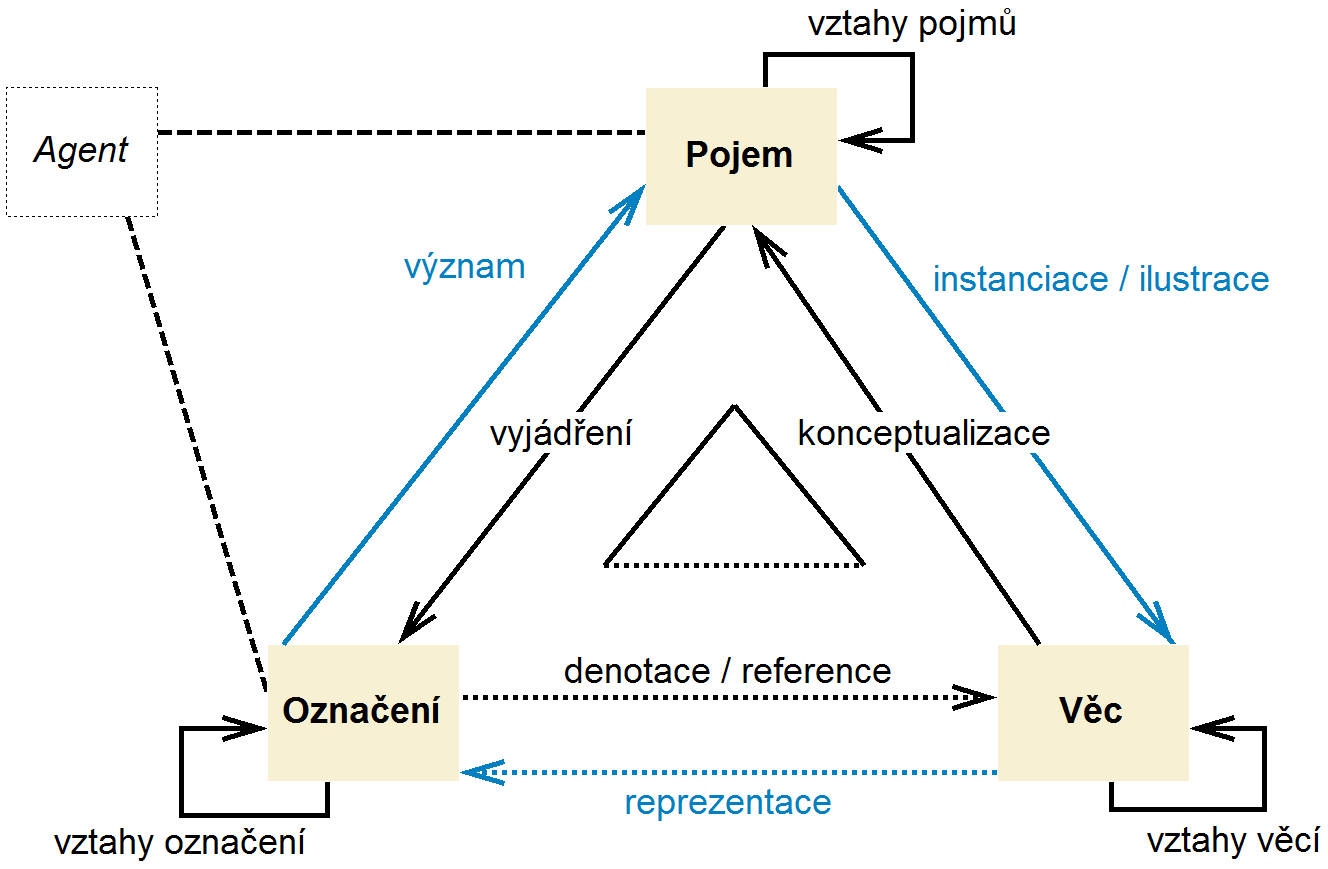
Obr. 3 Sémiotický trojúhelník
Sémiotický trojúhelník byl původně koncipován jako nástroj pochopení znaku. Informatické ontologie ho ovšem využívají jako kognitivní nástroj, umožňující pochopení vztahu reprezentace a konceptualizace reality. V našem znázornění sémiotického trojúhelníku na obrázku 3 je cokoli, co je součástí reality, zastoupeno pracovním termínem "Věc". Slovo věc nepoužíváme ve smyslu "materiální objekt", zastupuje pro naše účely i abstraktní entity a události, včetně informací a znalostí. V zájmu souladu s pojetím uplatněným v terminologických systémech a v systémech organizace znalostí jsou zbývající dva vrcholy trojúhelníka obsazeny entitami "Pojem" a "Označení".
Vztahy entit na vrcholech sémiotického trojúhelníku jsou znázorněny šipkami. Jak je z obrázku 3 zřejmé, jsou zastoupeny jak vztahy mezi různými typy entit, tak i vzájemné vztahy mezi entitami stejného typu. První skupinu tvoří binární asymetrické obousměrné vztahy věcí a pojmů, pojmů a označení a označení a věcí. Ve směru Věc -> Pojem -> Označení naznačeném šipkami na obrázku 3 sémiotický trojúhelník ukazuje cestu od skutečnosti k myšlení (pochopení) a od myšlenek k jejich vyjádření. V obráceném směru Označení -> Pojem -> Věc lze sledovat, jak jazyk zastupuje pojmy a jak pojmy zastupují realitu. Do druhé skupiny vztahů patří rekurzivní vzájemné vztahy pojmů, označení a věcí.
Sémantický vztah reprezentace mezi znakem a realitou, tj. "Označení <označuje> Věc" je na obrázku 3 znázorněn prostřednictvím tečkované čáry jako vztah nepřímý, zprostředkovaný konceptualizací a vyjádřením pojmů pomocí nějaké znakové soustavy. Konceptualizace je pojmový (myšlenkový) odraz (zpracování) představy o významu skutečnosti. Pojem jako takový je implicitní (nesdělitelný, tacitní), pro jeho komunikaci je nutné explicitní vyjádření pojmu označením. Vyjádření označuje situaci, kdy pojem je zastoupen znakem (tj. označen), nejčastěji ve formě nějakého jazykového výrazu. Význam je pojmová interpretace obsahu znaku. Instanciace/ilustrace vyjadřuje uskutečnění významu pojmu nebo jeho doložení příkladem. Denotace/reference je vztah, v němž znak označuje skutečnost, vypovídá (referuje) o realitě.
Ke třem faktorům na vrcholech sémiotického trojúhelníku se ještě někdy přidává čtvrtý – subjekt nebo agent, tj. ten, kdo pojmy tvoří ve své mysli či kognitivním systému (tím vyjadřujeme možnost, že v roli agenta může vystupovat nejen člověk, ale i stroj) a vyjadřuje je nějakými znaky.[1] Agent vnáší do sémiotického trojúhelníku subjektivní dimenzi, tj. jedinečný přístup každého individua k chápání významu, a dimenzi pragmatickou, tj. porovnání významu s tím, k čemu ho chce agent využít.[2] Pragmatický aspekt vztahu agenta k jím nahlížené realitě vyjadřuje vztah relevance mezi jeho kognitivní potřebou a mezi významem poznávané věci, tedy její použitelnost pro agenta. Vztah interakce mezi agentem a označením a agentem a pojmem znázorňuje na obrázku 3 přerušovaná čára.
[1] Například Ladislav Tondl používá pro subjekt označení „pozorovatel“, případně „uživatel jazyka“. TONDL, Ladislav. Problémy sémantiky. Praha: Karolinum, 2006, s. 30-31. ISBN 978-80-246-1075-7.
[2] Podrobněji viz např. HUDÁKOVÁ, Miriam. Nevyhnutelnost subjektivity při pořádání informací a znalostí. In: Ikaros [online]. 2006, 10(3) [cit. 2025-04-05]. urn:nbn:cz-ik3204. ISSN 1212-5075. Dostupné z: http://www.ikaros.cz/node/3204.
[1] ZDRÁHAL, Zdeněk. Ontologie: od filosofie k umělé inteligenci. In: Vladimír MAŘÍK, Olga ŠTĚPÁNKOVÁ, Jiří LAŽANSKÝ a kol. Umělá inteligence. 6. 1. vyd. Praha: Academia, 2013, s. 21-28. ISBN 978-80-200-2276-9.
[2] Tamtéž, s. 26.
[3] Je vhodné upozornit, že „realita“ v tomto pojetí zahrnuje nejen to, co aktuálně a prokazatelně existuje, ale i představy a myšlenkové konstrukce.
5.1. Využití ontologií pro komunikaci znalostí
„Klíčovým problémem komunikace je porozumění a pochopení smyslu sdělení.“[2] Převedeme-li tato slova Zdeňka Zdráhala do terminologie, použité při interpretaci sémiotického trojúhelníku, lze tuto úlohu formulovat slovy „od označení k pojmu“, což je hrana trojúhelníku označující vztah „význam“. Ontologie plní v rámci této úlohy funkci slovníku s explicitně definovanými významy zahrnutých pojmů.
V případě využití ontologií pro komunikaci znalostí je vhodné zdůraznit, že jde o komunikaci v obou jejích významech – tj. sdělování i sdílení. Sdělování znalostí spočívá v jejich přenosu v prostoru nebo v čase. Sdílení znalostí je založeno na existenci nějaké komunikační platformy, jež umožňuje spojení a společnou činnost. Rozpor mezi heterogenním sémantickým prostředím počítačových sítí a potřebou společné platformy pro komunikaci (interoperabilitu) pomáhají řešit právě ontologie ve funkci sémantického rozhraní. Protože uživateli ontologie mohou být nejen lidé, ale i technická zařízení, především počítačové programy, má ontologie za úkol zprostředkovat smysluplnou komunikaci jak mezi lidmi (člověk–člověk), tak mezi lidmi a počítačovými systémy (člověk–stroj) a dokonce i mezi počítačovými systémy navzájem (např. webové služby, inteligentní agenti, tj. komunikace stroj–stroj). Tedy všude tam, kde je třeba se domluvit s ostatními členy odborné komunity a zejména tam, kde se počítá s inteligentní softwarovou podporou takovéto komunikace, využijeme ontologie.
5.2. Využití ontologií pro opakované použití a organizaci znalostí
Ve schématu sémiotického trojúhelníku je tato funkce ontologie vyznačena interakcí agenta s pojmy a s jejich označeními. V této oblasti použití funguje ontologie jako opakovaně použitelný pojmový model (viz kapitola 4). Opakovatelné využití neboli znovupoužitelnost znalostí zachycených v ontologii se projevuje několika způsoby. Jednak tím, že ontologický pojmový model lze použít pro více různých zdrojů (v tom se liší například od jednoúčelových databázových schémat) a navíc jej může použít více různých uživatelů pro více různých účelů. Další možností je propojení s jinými ontologiemi. Ve všech případech je podmínkou jednotné chápání sémantiky znalostí těmi, kdo je vytvořili a zaznamenali a těmi, kdo je hodlají využít nebo zpracovat.
Tento způsob aplikace ontologií v praxi je nejtypičtějším případem využití tzv. lehkých terminologických ontologií (viz kapitola 6). Do značné míry se překrývá s tím, jak mají svůj cíl definován tradiční systémy organizace znalostí. Zjednodušeně řečeno, využívají se k popisu obsahu a struktury zaznamenaných organizovaných znalostí.
5.3. Využití ontologií k popisu skutečnosti pro její zpracování / podporu počítačovými systémy
Při úvahách o úloze nástrojů pro zpracování znalostí lze obrazně konstatovat, že zatímco cílem slovníků je nastolit pořádek mezi slovy a systém organizace znalostí se o totéž snaží u pojmů, vlastním zájmem ontologie je realita, již se snaží reprezentovat natolik explicitně, aby to bylo srozumitelné i počítačovým programům.[3] Zdeněk Zdráhal to formuluje následovně:
„Jednou ze základních součástí většiny informačních systémů je explicitní či implicitní popis (model, zobrazení) části reality, ke které se informační systém určitým způsobem vztahuje.“[4]
Tento případ užití chápe ontologii jako účelovou reprezentaci či model znalostí o skutečnosti, určenou k využití počítačovými systémy (tj. informačními systémy, softwarovými aplikacemi a službami). Koresponduje s tím, jak byla popsána úloha ontologií ve znalostních systémech (viz kapitola 4).
Sémiotický trojúhelník zobrazuje tuto úlohu trajektorií ve směru od věcí k pojmům a k jejich označení. V tomto směru ontologie podporují myšlenku sémantického webu, jehož cíl charakterizoval Tim Berners Lee lapidárně jako přechod od webu dokumentů k webu dat (angl. web of data)[5]. Tato vize předpokládá, že počítačové programy, které byly dosud využívány především k rychlé mechanické manipulaci se soubory dat (typicky k uložení a přenosu z jednoho místa na druhé), budou díky ontologiím schopny takových operací, které vyžadují porozumět obsahu dat – kategorizace, klasifikace, určení relevance ad.
[4] ZDRÁHAL, Zdeněk. Ontologie: od filosofie k umělé inteligenci. In: Vladimír MAŘÍK, Olga ŠTĚPÁNKOVÁ, Jiří LAŽANSKÝ a kol. Umělá inteligence. 6. 1. vyd. Praha: Academia, 2013, s. 21. ISBN 978-80-200-2276-9.
[5] „Data“ jsou v tomto případě metaforou pro informace a znalosti.
5.4. Využití ontologií pro automatické odvozování znalostí
Podmínkou úspěšné realizace této úlohy je opět jednotné chápání sémantiky pojmů kognitivními agenty (tj. lidmi i stroji). Využití ontologie pro automatické usuzování, odvozování a objevování nových znalostí umožňuje explicitní zachycení netriviálních vztahů mezi zahrnutými pojmy a pravidel vymezujících jejich validitu. Při odvozování se pak používá jazyk založený na některém z logických kalkulů (predikátová logika, deskripční logika ad.) Touto ambicí se ontologie přibližují k oboru umělé inteligence, v jejímž rámci ostatně byl termín „uveden do oběhu“ (viz kapitola 3.1).
6. Typologie informatických ontologií
Stejně jako nepanuje jednotné mínění o vymezení rozsahu a obsahu pojmu ontologie, existují i různé přístupy k jejich typologii. Kupříkladu typologie zpracovaná účastníky konference Ontology Summit 2016[1] zahrnuje následující typy:
- vrchní/vrcholové ontologie, ontologie vyšší úrovně (upper ontologies)
- referenční ontologie (reference ontologies)
- aplikační a lokální ontologie (application and local ontologies)
- překlenovací („přemosťující“) ontologie (bridge ontologies)
- obecné metadatové šablony a metadatová schémata (common metadata templates and metadata schema)
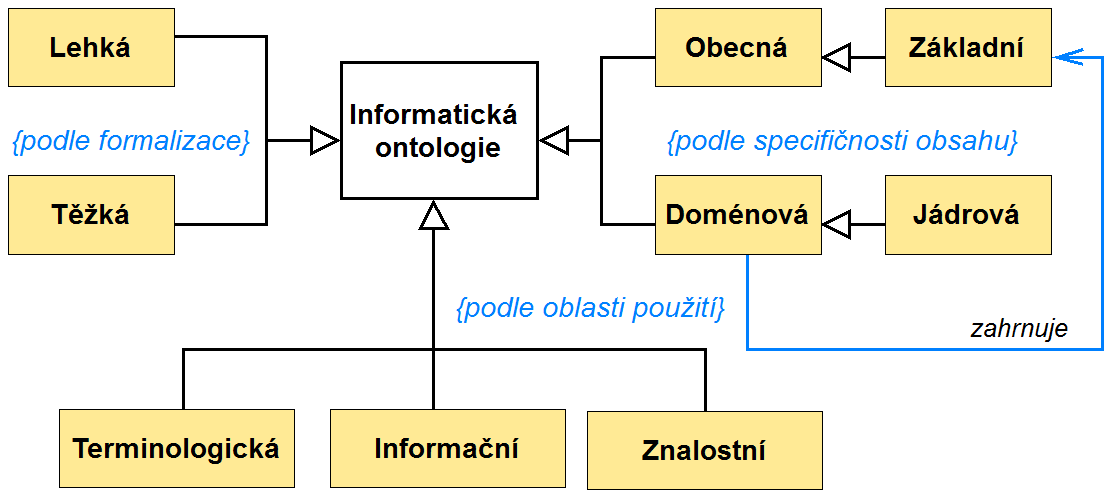
V následujícím stručném přehledu se zaměříme na tři kritéria členění, jež vedou ke vzniku tří rozdílných typologií: podle formalizace, podle oblasti použití a podle specifičnosti obsahu. Tyto tři typologie jsou schematicky znázorněny na obrázku 4 ve formě diagramu tříd UML. Je ovšem třeba upozornit, že obecně je pociťována absence přesných dělicích hranic mezi jednotlivými typy a převažuje pojetí typologie informatických ontologií jako plynulého spektra.
Obr. 4 Typologie informatických ontologií
[1] Ontology Summit 2016 communique: Ontologies within semantic interoperability ecosystems [online]. Donna Fritzsche, Michael Gruninger, ed. 2016 [cit. 2025-04-05]. Dostupné z: https://ontologforum.org/index.php/OntologySummit2016/Communique.
6.1. Typologie podle míry formalizace a typu konceptualizace
Charakter plynulých přechodů je patrný již v jedné z prvních typologií zpracované Michaelem Uscholdem a Michaelem Grűningerem[1], kteří člení ontologie podle míry formálnosti jazyka, v němž jsou jimi reprezentované znalosti vyjádřeny. Vysoce neformální ontologie jsou vyjádřené volně v přirozeném jazyce, semi-neformální ontologie jsou vyjádřené v omezené a strukturované formě přirozeného jazyka, semi-formální ontologie jsou vyjádřené v umělém, formálně definovaném jazyce a rigorózně formální ontologie obsahují přesně (striktně) definované termíny s formální sémantikou, teorémy a důkazy (např. vlastnosti bezespornosti nebo úplnosti), plně vyjádřitelné programovacím jazykem.
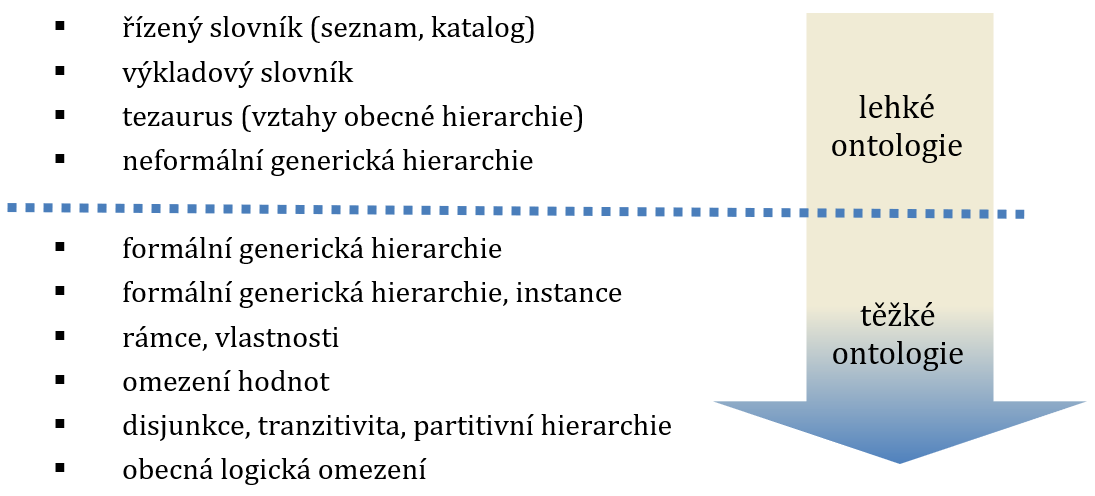
Typologie Debory L. McGuinnessové je další z často citovaných typologií ve formě spektra. Řadí informatické ontologie podle vyjadřovací (sémantické) síly a zároveň dle stupně formalizace. Jednotlivé typy znázorněné na obrázku 5 jsou označeny prostřednictvím pojmenování nástrojů, jež jsou pro daný typ ontologií charakteristické.[3]
Obr. 5 Typy ontologií podle Debory L. McGuinnessové
Autorka navíc člení toto plynulé spektrum na dvě skupiny, jež se obvykle označují jako tzv. lehké a těžké (angl. light-weight, heavy-weight) ontologie.[4]
Lehké ontologie obsahují pojmy, vztahy mezi pojmy a definice, jež popisují pojmy. Zahrnují tedy nástroje, pro něž se v oblasti knihovnictví používá termín „systém organizace znalostí“.
Za informatické ontologie v pravém slova smyslu se zpravidla považují až systémy s formální generickou hierarchií. Rovněž podle normy ISO 25964, jež ontologie uvažuje v kontextu systémů organizace znalostí, je účelné za ontologie považovat pouze těžké ontologie.[5] Přínos těžkých ontologií oproti tradičním systémům organizace znalostí spočívá v bohatší sémantice pojmů i jejich vztahů, vyšším stupni formalizace a v těsnějším sepětí s informačními a komunikačními technologiemi.
Pojmy těžkých ontologií jsou stejně jako v lehkých ontologiích určeny označením, definicemi a navíc vymezením svých vlastností. Obsahují více omezení, jež vyjasňují význam zahrnutých pojmů. Dalším přínosem je bohatší sémantika vztahů – za těžké ontologie se považují systémy schopné vyjádřit komplexnější vztahy mezi pojmy, než jsou obecné vztahy ekvivalence, hierarchie a asociace, obvyklé například v knihovnických klasifikacích a v tezaurech, případně v databázových schématech. Sémantika těžkých ontologií je nejen explicitně vyjádřena, ale i formalizována prostřednictvím logických axiomů, omezení nebo pravidel. Jednoznačně a formalizovaně vymezená sémantika pojmů umožňuje automatické odvozování znalostí. Odvozovat je možné nejen na deklarativní (pojmové) úrovni, ale i na úrovni procesů v plánovacích a analytických úlohách. Významnou součástí těžké ontologie je obvykle software, který umožňuje její vytvoření, editaci i využití.
Lze konstatovat, že rozdíl mezi lehkými a těžkými ontologiemi se projevuje i v možnostech jejich využití (viz část 3). Všechny oblasti užití jsou zpravidla schopny pokrýt pouze těžké ontologie, oblasti užití lehkých ontologií se obvykle omezují na první dva uvedené okruhy, tj. na podporu komunikace a opakovaného využití a organizace znalostí.
[1] USCHOLD, Michael, GRÜNINGER, Michael. Ontologies: principles, methods and applications [online]. Edinburgh: February 1996 [cit. 2025-04-05], s. 6. Technical Report, AIAI-TR-191. University of Edinburgh, School of Informatics, Artificial Intelligence Applications Institute. Dostupné z: https://www.aiai.ed.ac.uk/publications/documents/1996/96-ker-intro-ontologies.pdf.
[2] McGUINNESS, Deborah L. Ontologies come of age. In: FENSEL, Dieter, HENDLER, James A., LIEBERMAN, Henry, WAHLSTER, Wolfgang, ed. Spinning the semantic Web: bringing the World Wide Web to its full potential. 1st ed. Cambridge (Mass.): MIT Press, 2003, s. 171-196. ISBN 978-0-26256212-6 (brož.). ISBN 978-0-262-06232-9 (váz.).
[3] GÓMEZ-PÉREZ, Asunción, FERNÁNDEZ-LÓPEZ, Mariano, CORCHO, Oscar. Ontological engineering: with examples from the areas of knowledge management, e-commerce and the semantic web. 1st ed. London: Springer, 2004, s. 8. https://doi.org/10.1007/b97353. ISBN 978-1-85233-551-9 (print). ISBN 978-1-85233-840-4 (online).
[4] ISO 25964-2:2013. Information and documentation – Thesauri and interoperability with other vocabularies – Part 2: Interoperability with other vocabularies. 1st ed. Geneva: International Organization for Standardization, 2013-03-04, s. 72-73.
[5] SVÁTEK, Vojtěch. Ontologie a WWW. In: Dušan CHLAPEK, ed. DATAKON 2002: sborník databázové konference: Brno, Česká republika, 19.-22. října 2002. Brno: Masarykova univerzita, 2002, s. 29-30. ISBN 978-80-210-2958-3.
6.2. Typologie ontologií podle oblasti použití
Zajímavou typologii, již nazývá členění „podle historických paradigmat“, představuje Vojtěch Svátek[6] v podobě členění na terminologické, informační a znalostní ontologie. Tato typologie odráží existenci různých odborných komunit, jež ontologie vytvářejí a používají, a jimi aplikovaných vědních disciplín.
Terminologické či lexikální ontologie[7] využívají obory terminologie, jazykověda, informační věda a knihovnictví. Jejich jádrem je formalizovaný slovník, tj. zahrnují řízené slovníky a systémy organizace znalostí. V komunitě paměťových a fondových institucí se pro ně aktuálně používá označení slovníky metadat (angl. value vocabularies).[8] Obvykle spadají do kategorie lehkých ontologií. Příkladem je ontologie WordNet nebo tezaurus AGROVOC. John F. Sowa je definuje jako ontologie, jejichž kategorie nemusejí být plně specifikovány axiomy a definicemi a terminologickou ontologii staví do protikladu k tzv. axiomatizované ontologii, což je podle něj
„ontologie, jejíž kategorie jsou rozlišeny pomocí axiomů a definic uvedených v jazyce logiky nebo v nějakém počítačovém jazyce, jenž může být automaticky do logického jazyka přeložen.“
Sowa zároveň konstatuje, že rozdíl mezi axiomatizovanou a terminologickou ontologií je spíše záležitostí míry axiomatizace a možností automatického odvozování a definování než rozdíl v typu.[9]
Teoretickým základem informačních ontologií je informatika. Zahrnují datové modely a metadatová schémata (tj. modely struktury metadat, angl. metadata element sets). Typickým zástupcem tohoto typu ontologií jsou Abstraktní model DCMI[10] nebo ontologický metamodel ODM[11].
Znalostní ontologie tvoří formalizované logické teorie (např. základní ontologie KR Ontology navržená J. F. Sowou). Obvykle spadají do kategorie těžkých ontologií, jejich teoretickým základem je logika a umělá inteligence.
[7] Viz např. LACASTA, Javier, NOGUERAS-ISO, Javier, ZARAZAGA-SORIA, Francisco Javier. Terminological ontologies: design, management and practical applications. New York: Springer, 2010. xvii, 197 s. Semantic Web and Beyond. Computing for Human Experience, vol. 9, ISSN 1559-7474. https://doi.org/10.1007/978-1-4419-6981-1. ISBN 978-1-4419-6980-4 (print). ISBN 978-1-4419-6981-1 (online).
[8] ISAAC, Antoine, WAITES, William, YOUNG, Jeff, ZENG, Marcia. Library Linked Data Incubator Group: Datasets, value vocabularies, and metadata element sets [online]. W3C Incubator Group report 25 October 2011. W3C, 2011 [cit. 2025-04-05]. Dostupné z: http://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset-20111025/.
[9] SOWA, John F. Knowledge representation: logical, philosophical, and computational foundations. Pacific Grove: Brooks/Cole, © 2000. s. 493-497. Computer Science Series. ISBN 978-0-534-94965-5.
[10] POWELL, Andy, NILSSON, Mikael, NAEVE, Ambjörn, JOHNSTON, Pete, BAKER, Thomas. DCMI abstract model. DCMI, 2007-06-04 [cit. 2025-04-05]. Dostupné z: http://dublincore.org/documents/abstract-model/.
[11] Object Management Group. Ontology definition metamodel (ODM) [online]. Version 1.1. Needham (MA, USA): Object Management Group, September 2014 [cit. 2025-04-05]. 348 s. OMG Document Number: formal/2014-09-02. Dostupné z: http://www.omg.org/spec/ODM/.
6.3. Typologie podle povahy zahrnutých entit / podle specifičnosti
Tato typologie se zaměřuje na povahu univerza diskurzu stanoveného pro danou ontologii. Podle toho, jak je vymezena množina jimi reprezentovaných entit, se ontologie člení na obecné (též univerzální, angl. generic) a doménové (angl. domain).
Obecné ontologie jsou všeobecně zaměřené, doménově nezávislé a co do rozsahu neohraničené. Příkladem obecné ontologie je DBpedia Ontology[12], vytvořená z označení položek infoboxů v článcích Wikipedie. Obdobně ontologie Schema.org zahrnuje témata používaná k označení obsahu webových stránek, jež byla shromážděná provozovateli internetových vyhledávačů. YSO – General Finnish ontology[13] je příkladem obecné ontologie vzniklé v prostředí paměťových a kulturních institucí.
Specifickým typem obecných ontologií jsou základní (angl. foundational) / vrchní (angl. upper, top level) ontologie, nazývané též ontologie vyšší úrovně. Stefano Borgo a Claudio Masolo charakteristiku základních ontologií shrnují následovně:
„1. mají velký rozsah, 2. jsou ve vysoké míře opětovně použitelné v různých modelovacích scénářích, 3. mají dobré filozofické a konceptuální základy, a 4. jsou sémanticky transparentní a (proto) bohatě axiomatizované.“[14]
Účelem základních ontologií je sloužit jako výchozí bod pro tvorbu nových doménových ontologií. Obsahují vícenásobně použitelné entity, obvykle základní kategorie na nejvyšší úrovni obecnosti a někdy i návrhové vzory. Vztah základní ontologie a doménové ontologie vytvořené s její pomocí je hierarchický (inkluzivní), tj. doménová ontologie zahrnuje, typicky na nejvyšší hierarchické úrovni, pojmy převzaté ze základní ontologie. Příklady základních ontologií jsou BFO – Basic formal ontology[15] a DOLCE.
Doménové ontologie se omezují na konkrétní oblast. Příkladem doménově specifické ontologie je genová ontologie GO – Gene ontology[16]. Doménu lze vymezit nejen tematicky, ale i problémově – tak by bylo možné rozlišovat mezi ontologiemi orientovanými na deskriptivní a na procedurální znalosti (viz např. ontologie webových služeb OWL-S[17]). Zvláštním typem doménové ontologie je tzv. jádrová (angl. core) ontologie, obsahující centrální pojmy domény.
[12] Dostupné z: https://www.dbpedia.org/resources/ontology/ [cit. 2025-04-05].
[13] Dostupné z: https://finto.fi/yso/ [cit. 2024-05-08].
[14] BORGO, Stefano, MASOLO, Claudio. Foundational choices in DOLCE. In: STAAB, Steffen, STUDER, Rudi, ed. Handbook on ontologies. 2nd ed. Dordrecht: Springer, 2009, s. 361. https://doi.org/10.1007/978-3-540-92673-3_16. ISBN 978-3-540-70999-2 (print). ISBN 978-3-540-92673-3 (online).
[15] Dostupné z: https://basic-formal-ontology.org/ [cit. 2025-04-05].
[16] Dostupné z: https://geneontology.org/ [cit. 2025-04-05].
[17] Dostupné z: https://www.w3.org/Submission/OWL-S/ [cit. 2025-04-05].
ISO/IEC 21838-1:2021. Information technology - Top-level ontologies (TLO): Part 1: requirements. Dostupné z: https://www.iso.org/standard/71954.html
7. Informatické ontologie a systémy organizace znalostí
Porovnáme-li pojmový obsah pracovní definice informatické ontologie, zformulované v kapitole 2, s pojmovým obsahem definice systému organizace znalostí (SOZ)[1], jsou patrné významné analogie a v mnoha případech i shoda pojmů, na nichž jsou tyto definice založeny. V obou případech se jedná o specifický typ pojmového modelu, základním strukturním prvkem SOZ i informatických ontologií je pojem. Lze tedy konstatovat, že oba pojmy mají společný nejbližší nadřazený rod (genus proximum), jímž je pojmový model. Shodu lze najít i v rozlišujících druhových rozdílech (differentia specifica), které oba tyto specifické typy odlišují od jiných typů pojmových modelů. Jak SOZ, tak informatické ontologie jsou inženýrské artefakty, jejichž funkcí je podpora procesů organizace znalostí, oba jsou opakovaně použitelné a sdílené rozsáhlejším okruhem uživatelů.
Vzájemný vztah systémů organizace znalostí a ontologií je vnímán různými způsoby.[2] Výše uvedené společné rysy SOZ a informatických ontologií vedou některé autory zejména z oblasti informatiky k tomu, že používají označení „ontologie“ souhrnně jak pro informatické ontologie, tak pro jednotlivé typy SOZ. Takové pojetí tedy chápe SOZ jako podmnožinu informatických ontologií. V tomto textu se pokusíme předložit alternativní pohled, v jehož rámci nahlížíme SOZ a informatické ontologie jako dvě sice rozdílné, ale částečně se překrývající množiny.
Při porovnání vyjdeme z typologie informatických ontologií, představené v kapitole 6, a z níže uvedené typologie SOZ. Konkrétně využijeme členění ontologií na lehké (terminologické) a těžké (znalostní) a členění SOZ na slovníky, klasifikace a pojmové sítě. V obou případech lze konstatovat, že ve skutečnosti se nejedná o zřetelně ohraničené a oddělené skupiny, ale spíše o orientační body v rámci plynulého spektra, v němž jsou jednotlivé typy řazeny podle své sémantické síly.
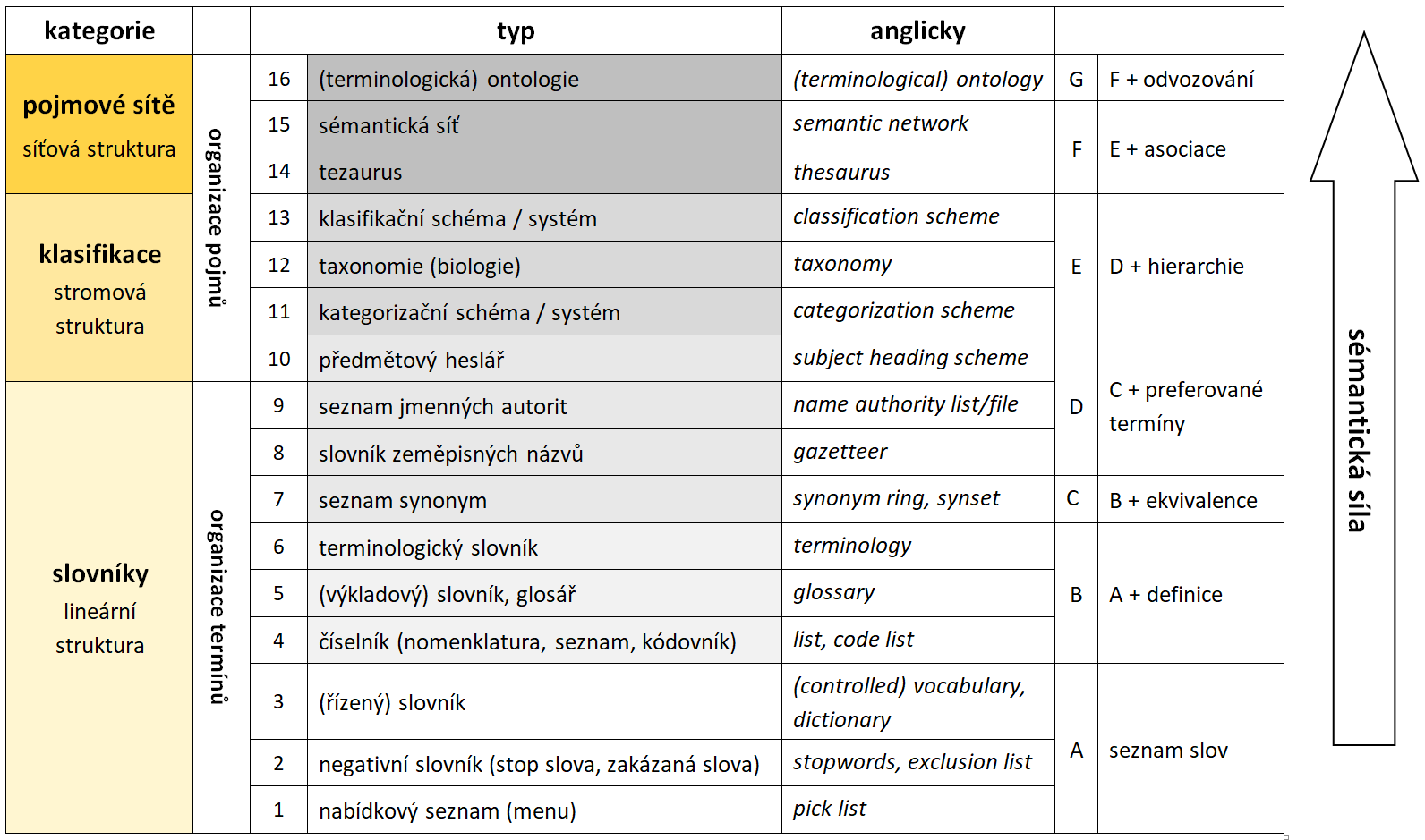
Obr. 6 Typologie systémů organizace znalostí
S využitím této typologie lze uvažovat tři stupně sémantické síly, k nimž lze jednotlivé typy přiřadit:
1. V první skupině jsou SOZ s nejnižší sémantickou sílou, v nichž převažuje důraz na funkce slovníku či terminologie. Tato skupina zahrnuje SOZ ze skupiny označené jako slovníky (tj. typy 1–9 v tabulce na obrázku 6).
2. Druhá skupina se střední sémantickou sílou zahrnuje SOZ orientované na pojmy – klasifikace a pojmové sítě (tj. typy 10–16 v tabulce na obrázku 6). Do této skupiny řadíme rovněž lehké (terminologické) ontologie. Klíčovým procesem je klasifikace, tj. spojování a oddělování zkoumaných entit na základě podobnosti a odlišnosti.
3. Třetí skupina zahrnuje těžké (znalostní) ontologie s nejvyšší sémantickou sílou. Jak bylo uvedeno v části 6.1, tento typ ontologií disponuje kromě uvedených společných rysů se SOZ ještě specifickými vlastnostmi. Klíčovým procesem je konceptualizace, tj. tvorba pojmové reprezentace (modelu) zkoumané skutečnosti. Ontologické pojmy (třídy) mají explicitně definované vlastnosti a axiomaticky definovanou sémantiku. Funkce těžkých ontologií jsou oproti lehkým ontologiím rozšířeny o komunikaci, opakované využití znalostí, popis skutečnosti pro počítačové zpracování a především automatické odvozování.
Členění na tři výše uvedené skupiny demonstruje chápání vztahu SOZ a informatických ontologií jako průniku dvou množin: první skupina zahrnuje výhradně SOZ, druhá skupina představuje průnik množin SOZ a informatických ontologií a ve třetí skupině jsou opět výhradně informatické ontologie.
[1] „Systém organizace znalostí je schéma, modelující strukturu (tj. prvky a vzájemné vztahy) organizované množiny zaznamenaných znalostí. Funkcí systému organizace znalostí je podpora procesů organizace znalostí a přístupu ke znalostem. Základním strukturním prvkem systému organizace znalostí je pojem. Jádrem fyzické reprezentace každého systému organizace znalostí je slovník, tj. formální vyjádření pojmů“. Viz definice SOZ v TDKIV: https://aleph.nkp.cz/F/?func=direct&doc_number=000016487&local_base=KTD.
[2] Viz např. úvodník k monotematickému číslu časopisu Applied ontology, věnovanému vztahu ontologií a terminologických systémů: GRABAR, Natalia, HAMON, Thierry, BODENREIDER, Olivier. Ontologies and terminologies: continuum or dichotomy? In: Applied ontology. 2012, 7(4), 375-386. https://doi.org/10.3233/AO-2012-0119. ISSN 1570-5838 (print). ISSN 1875-8533 (online).
8. Metody návrhu ontologie
Již bylo konstatováno, že informatické ontologie na rozdíl od ontologií filozofických nejsou výsledkem vědeckého zkoumání, ale jsou to navrhované a konstruované artefakty. Přístup k návrhu informatických ontologií prodělal analogický vývoj jako v případě počítačových programů a znalostních systémů, jen s cca třicetiletým časovým posunem: od původního pojetí návrhu ontologie jako umění či vědy, dostupných jen několika výjimečně disponovaným jedincům, k inženýrství. Analogicky k softwarovému a znalostnímu inženýrství se zformovala nová inženýrská disciplína – ontologické inženýrství.
Jako inženýrství (angl. engineering) se označuje systematická aplikace vědeckých znalostí při návrhu a tvorbě cenově efektivních řešení praktických problémů. Uplatňuje se při tvorbě rozsáhlých, složitých a technologicky náročných artefaktů. Inženýrské řešení respektuje existující standardy a je dokumentováno. Na rozdíl od teoretického výzkumu má inženýrství vždy výrazný etický aspekt.
Obecný postup inženýrského návrhu vychází z předem určeného cíle, existujících omezení a požadované spolehlivosti. Samotnému návrhu předchází analýza problému, následuje volba metodiky a nástrojů. Klíčovým procesem je modelování a návrh řešení. Následují procesy implementace navrženého řešení (výroba, realizace, správa).
Východiskem pro metody ontologického inženýrství jsou především metody systémového a softwarového inženýrství a metody fasetové analýzy.
Ontologické inženýrství zahrnuje soubor aktivit, jež se týkají procesu vývoje, životního cyklu a metod tvorby (konstrukce) ontologií a pomůcek (například jazyků), jež tyto aktivity podporují. Kromě obvyklých obecných inženýrských procesů (analýza, návrh, testování, implementace, správa) se ontologické inženýrství zaměřuje i na specifické oblasti mapování, integrace, sdílení a opětovného použití ontologií. Analogicky ke CASE systémům v softwarovém inženýrství už jsou k dispozici i specializované softwarové nástroje podporující návrh ontologií (Protégé, Ontopia ad.).
V ontologickém inženýrství se uvažují čtyři typy aktérů. Kromě ontologického/znalostního inženýra se zpravidla vývoje účastní ještě doménový specialista / odborník a ve stále větší míře i koncový uživatel – osoba. Dalším uvažovaným subjektem je počítačová aplikace (agent) v roli uživatele ontologie.
První krok směrem ke standardizaci tvorby ontologií učinil v roce 1995 Thomas Gruber. Zformuloval obecná kritéria, jež doporučil sledovat během návrhu ontologií, a jejich použitelnost doložil dvěma případovými studiemi.[1]
1. Jasnost, srozumitelnost: Každý pojem reprezentovaný termínem má mít objektivní (jednoznačnou, přesnou a kontextově nezávislou) definici. Preferují se formální definice tvořené logickými axiomy. Definice mají být úplné, tj. mají splňovat jak logické podmínky nutnosti, tak podmínky postačitelnosti.
2. Soudržnost: Povoleno je jen takové odvozování, které je v souladu s obsahem definic termínů.
3. Rozšiřitelnost: Rozšiřování a specializace ontologie má umožnit monotónní usuzování, tj. definování nových termínů nemá vyžadovat revizi existujících definic.
4. Minimální závislost na znakovém (kódovém) systému: Konceptualizace, tj. pojmová reprezentace skutečnosti, má být provedena na úrovni znalostí a nemá být omezována zvoleným typem notace nebo kódování.
5. Minimální ontologické závazky: Termíny v ontologii mají mít svůj význam co nejméně omezen, pouze v míře nezbytně nutné pro komunikaci.
Tato kritéria patří k základním principům ontologického inženýrství. Nezapřou své kořeny v pravidlech klasické formální logiky. Dalším rysem, který zase odkazuje na principy organizace znalostí v knihovnách, je orientace na flexibilitu a jednoduchost systému. Požadavek minimálních ontologických závazků je analogický požadavku Seymoura Lubetzkyho z roku 1953 na zjednodušení katalogizačních pravidel, formulovanému slavnou otázkou: „Jsou všechna tato pravidla nezbytná?“[2]
1. Specifikace požadavků
Stejně jako v softwarovém inženýrství se aktivity ontologického inženýrství zahajují specifikací požadavků.
Podle terminologické normy ISO/IEC 2382 je požadavek (angl. requirement) „základní podmínka, kterou musí systém splňovat“.[3] Požadavky se obvykle člení na funkční a ne-funkční. Funkční požadavky stanoví, co má systém dělat a jsou specifikovány prostřednictvím případů užití. Ne-funkční požadavky určují, za jakých podmínek bude systém plnit stanovené funkce. Jsou specifikovány pomocí ontologických závazků.

Obr. 7 Struktura specifikace požadavků na ontologii
Případem užití rozumíme zaznamenaný požadavek, určující, co má systém vykonávat či jak se má chovat vzhledem ke konkrétnímu aktérovi (např. k uživateli). Případy užití se často specifikují formou scénářů pro používání systému; každý scénář obsahuje sekvenci (posloupnost) událostí, které v jeho rámci probíhají. Specifickým typem případu užití v ontologickém inženýrství je zodpovídání tzv. kompetenčních otázek (angl. competency questions). Pojem kompetenční otázky zavedli do ontologického inženýrství v rámci své metodiky TOVE Michael Grüninger a Mark S. Fox.[4] Definují je jako otázky, na něž má být ontologie schopna poskytovat odpovědi, a doporučují, aby každý objekt v ontologii byl spojen s nějakou otázkou, k jejímuž zodpovězení má přispět. Aldo Gangemi s Valentinou Presuttiovou dále upřesňují, že kompetenční otázka je „typický dotaz, který by odborník mohl chtít položit za určitým účelem znalostní bázi ze své cílové domény. Správná doménová ontologie by měla specifikovat všechny a zároveň pouze ty konceptualizace, potřebné k zodpovězení kompetenčních otázek formulovaných odborníky nebo získaných od nich.“[5]
Termín ontologické závazky (angl. ontological commitment) se používá i ve filozofii, kam jej zavedl Willard Van Orman Quine[6]. V kontextu informatických ontologií se tímto termínem označují předpoklady, pravidla a omezení uplatňovaná při konstrukci ontologie. V negativním slova smyslu se též označují jako cognitive bias (kognitivní zkreslení). V užším slova smyslu představují ontologické závazky dohodu uživatelů ontologie o významu používaných znaků (slov, termínů) pro vyjádření pojmů a jejich vztahů. Plní obdobnou úlohu jako integritní omezení a tzv. business rules (obchodní pravidla, aplikační logika) v databázových systémech.
2. Analýza a návrh
Pro analytickou a návrhovou fázi tvorby ontologie jsou k dispozici různé metodiky.[7] V této části jsou uvedeny dvě z nich - metodika Williama Dentona a Louise Spiteriové s kořeny a zamýšleným využitím v oblasti informační vědy a metodika OntoClean, jejíž autoři působí v oblasti ontologického inženýrství.
Metodika Williama Dentona a Louise Spiteriové
V oblasti informační vědy se vyprofilovala metodika, která syntetizuje vybrané teoretické kánony, postuláty a principy S. R. Ranganathana a teorie britské Skupiny pro výzkum klasifikace (CRG). Louise F. Spiteriová s jejich využitím vytvořila a v roce 1998 publikovala zjednodušenou metodiku fasetové analýzy určenou původně pro účely výuky studentů knihovní a informační vědy na Dalhousieově univerzitě v Halifaxu.[8] V roce 2003 dopracoval William Denton tuto metodiku do podoby vhodné pro tvorbu fasetové klasifikace určené pro publikování webového obsahu.[9] Dentonova metodika se stala de facto standardem tvorby jednoduchých fasetových klasifikací v prostředí webu a dočkala se i aktualizace a přepracování do podoby ontologického návrhového vzoru.[10]
Východiskem jsou čtyři fáze tvorby fasetové klasifikace, jež v roce 1960 definoval člen CRG Brian Campbell Vickery :
1. Roztřídění termínů v dané oblasti do homogenních, navzájem se vylučujících faset, z nichž každá je odvozena z nadřazeného univerza podle jednoho kritéria členění;
2. Určení pořadí, v němž budou fasety použity ke konstrukci složených hesel;
3. Vytvoření takové notace pro dané schéma, jež dovolí plně flexibilní kombinaci termínů a jež rozmístí předměty do preferovaného pořadí (angl. filling order);
4. Použití fasetového schématu takovým způsobem, že umožní jak specifické odkazy, tak požadovanou úroveň obecného průzkumu.
V metodice navržené Williamem Dentonem jsou Vickeryho fáze doplněny o další tři fáze. Ústřední fáze – vytvoření a uspořádání faset, jsou založeny na zjednodušeném modelu fasetové analýzy, který vypracovala Louise Spiteriová. Ve vodopádovém životním cyklu se uplatňují četné prvky iterace, v jednotlivých fázích se střídavě užívají postupy top-down a bottom-up. Klíčové fáze a činnosti, jež probíhají v jejich rámci, jsou znázorněny v následující tabulce.
| Fáze | Rovina díla dle S. R. Ranganathana | Činnosti v rámci fáze |
| Shromáždění entit | rovina idejí (idea plane) - analýza domény (věcné oblasti) | Shromáždění reprezentativního vzorku entit pro danou doménu; u malých kolekcí je doporučeno zahrnout entity z celé domény. Jaké věci ontologie zahrne? Produkt: Pojmy reprezentující věci ve zvolené doméně. |
| Popis entit | rovina jazyka (verbal plane) | Vytvoření popisu jednotlivých entit. Sémantický rozklad popisů – rozdělení vět na části, přeuspořádání slov, rozpoznání základních pojmů v jednotlivých částech vět a jejich izolování. Jak vyjádříme pojmy? Jak vymezíme (definujeme) význam pojmů? Produkt: Názvy tříd (termíny) a jejich definice. |
| Vytvoření faset | rovina idejí (idea plane) | Prozkoumání výsledných termínů a nalezení obecných kategorií na nejvyšší úrovni, vyskytujících se ve všech entitách. Omezení nalezených kategorií na množinu vzájemně se vylučujících a ve svém celku vyčerpávajících faset, použitelných pro všechny termíny vytvořené v předchozí fázi. V rámci výběru faset se uplatňují následující principy:
Produkt: Vzájemně se vylučující a ve svém celku vyčerpávající kategorie, použitelné pro všechny věci určené ve fázi 1. |
| Uspořádání faset | rovina idejí (idea plane) rovina jazyka (verbal plane) |
Naplnění faset termíny vytvořenými ve fázi Popis entit, tak aby bylo možné zatřídit všechny shromážděné entity. Uspořádání termínů uvnitř fasety podle zvoleného principu (abecední, hierarchický, chronologický ad.). Volba preferovaných termínů, tvorba řízeného slovníku. |
| Určení pořadí faset | rovina notace (notational plane) | Rozhodnutí o standardním (defaultním) uvádění pořadí faset (např. na domovské stránce). |
| Klasifikace | Zatřídění celého obsahu domény. Analýza všech entit za použití faset a použití správných termínů pro popis každé entity. | |
| Revize, testování, správa | Při jakýchkoli problémech zjištěných v etapě klasifikace následuje iterace – návrat k předchozí fázi, jež je relevantní k vyřešení problému. Následuje uživatelské testování a pravidelná správa klasifikace (změna terminologie, nové entity, změny v doméně). |
Metodika OntoClean
Autoři této metodiky Nicola Guarino a Christopher Welty[11] konstatují, že je založena na obecných ontologických pojmech převzatých z filozofie. Připomínají, že v praxi modelování světa pro účely návrhu informačního systému lze vidět paralely s filozofií, jež se pokouší popsat svět formalizovaným a logickým způsobem. Lze konstatovat, že principy, na nichž je metodika založena, jsou v souladu s obecnými pravidly formálně správné analýzy, odvozenými z logiky.
Metodika je zaměřena na testování ontologie – kontroluje správnost a konzistenci navržené ontologie testováním vlastností jejích tříd. Vlastnosti jsou v rámci této metodiky chápány formalizovaně jako unární predikáty predikátové logiky prvního řádu. Autoři tedy pracují s vlastností jako s významem (intenzí) výroku o třídě typu ‚být čtenářem‘, ‚mít krevní skupinu‘. Podstata metodiky spočívá v určení čtyř metavlastností pro vlastnosti každé třídy: esencialita, rigidita, identita, jednota. Následně se tyto metavlastnosti aplikují na pravidla generické hierarchie. Přínosem metodiky je především to, že umožňuje na dostatečně formalizované úrovni zdůvodnit správnost zvolených řešení v konstrukci ontologie.
Esencialita (angl. essence) označuje takovou vlastnost, kterou entita musí mít. Přesněji řečeno, esenciální vlastnost musí mít každá instance třídy, pro niž je vlastnost definována (jež je jejím definičním oborem). Tato vlastnost je tedy v souladu s logickou podmínkou nutnosti.
Rigidita je speciální typ esenciality. Vlastnost je rigidní, pokud je esenciální ve všech svých případech. Jinými slovy, tuto vlastnost musí mít každá instance po celou dobu své existence. Rigidita koresponduje s aristotelským pojmem podstatné vlastnosti. Všechny třídy, jež mají rigidní vlastnosti, tvoří tzv. páteřní taxonomii ontologie.
Identita slouží k rozlišení instancí téže třídy. Každá entita v ontologii by měla mít určité kritérium identity a rigidní vlastnosti, které toto kritérium identity popisují. Tato vlastnost má stejnou funkci, jakou plní v prostředí relačních databází tzv. primární klíč.
Jednota určuje, v jakém vztahu jsou části určité entity k celku – slouží k rozlišení části instance od zbytku světa pomocí sjednocující relace. Třída má tuto vlastnost, pokud existují partitivní vztahy pouze mezi jejími instancemi a žádná instance není částí externího celku. Tato vlastnost je v souladu s doporučením, aby partitivní vztahy byly definovány jako monohierarchické (viz např. doporučení v normě ISO 25964-1).
Při uplatnění metodiky se postupuje následovně: V prvním kroku se každé vlastnosti přidělí metavlastnosti. Druhý krok se zaměřuje na ty vlastnosti, jež byly označeny jako rigidní, a na tvorbu páteřní taxonomie. Ve třetím kroku se na páteřní taxonomii uplatní principy stanovené pro metavlastnosti: kontrola identity a kontrola jednoty. Čtvrtý krok posuzuje nerigidní vlastnosti. V pátém kroku se do upravené páteřní taxonomie doplní další třídy a vztahy.
[1] GRUBER, Thomas R. Toward principles for the design of ontologies used for knowledge sharing. In: International journal of human-computer studies. November/December 1995, 43(5-6), 907-928. https://doi.org/10.1006/ijhc.1995.1081. ISSN 1071-5819.
[2] LUBETZKY, Seymour. Cataloging rules and principles: a critique of the A.L.A. rules for entry or entry and a proposed design for their revision. Washington: Library of Congress, 1953, s. 1.
[3] ISO/IEC 2382:2015. Information technology – Vocabulary [online]. 1st ed. Geneva: International Organization for Standardization, 2015-05 [cit. 2025-04-05]. Dostupné z: https://www.iso.org/standard/63598.html.
[4] GRÜNINGER, Michael, FOX, Mark S. Methodology for the design and evaluation of ontologies. In: Workshop on basic ontological issues in knowledge sharing, held in conjunction with IJCAI-95 [online], Montreal, 1995, s. 1-10 [cit. 2025-04-05]. Dostupné z: http://www.eil.utoronto.ca/wp-content/uploads/enterprise-modelling/papers/gruninger-ijcai95.pdf.
[5] GANGEMI, Aldo, PRESUTTI, Valentina. Ontology design patterns. In: STAAB, Steffen, STUDER, Rudi, ed. Handbook on ontologies. 2nd ed. Dordrecht: Springer, 2009, s. 230-231. https://doi.org/10.1007/978-3-540-92673-3_10. ISBN 978-3-540-70999-2 (print). ISBN 978-3-540-92673-3 (online).
[6] Viz PEREGRIN, Jaroslav. Kapitoly z analytické filosofie. 2. vyd. Praha: Filosofia, 2014, s. 196. ISBN 978-80-7007-420-6.
[7] Přehled metod ontologického inženýrství lze najít např. v článku: KUČEROVÁ, Helena. Metodiky ontologického inženýrství. In: Ikaros [online]. 2011, 15(5) [cit. 2025-04-05]. urn:nbn:cz:ik-13630. ISSN 1212-5075. Dostupné z: http://www.ikaros.cz/node/13630.
[8] SPITERI, Louise F. A simplified model for facet analysis: Ranganathan 101. In: Canadian journal of information and library science. April-July 1998, 23(1-2), 1-30. ISSN 1195-096X (print). ISSN 1920-7239 (online).
[9] DENTON, William. How to make faceted classification and put it on the web [online]. [Personal web site]: November 2003 [cit. 2023-04-22]. Dostupné z: http://www.miskatonic.org/library/facet-web-howto.html.
[10] RODRIGUEZ-CASTRO, Bene, GLASER, Hugh, CARR, Leslie. How to reuse faceted classification and put it on the semantic web. In: Peter F. PATEL-SCHNEIDER et al., ed. The Semantic Web – ISWC 2010: 9th International Semantic Web Conference, ISWC 2010, Shanghai, China, November 7-10, 2010: Revised Selected Papers, Part I. Berlin: Springer, © 2010, s. 663-678. Lecture Notes in Computer Science, no. 6496, ISSN 0302-9743. https://doi.org/10.1007/978-3-642-17746-0_42. ISBN 978-3-642-17745-3 (print). ISBN 978-3-642-17746-0 (online).
[11] GUARINO, Nicola, WELTY, Christopher A. An overview of OntoClean. In: STAAB, Steffen, STUDER, Rudi, ed. Handbook on ontologies. 2nd ed. Dordrecht: Springer, 2009, s. 201-220. https://doi.org/10.1007/978-3-540-92673-3_9. ISBN 978-3-540-70999-2 (print). ISBN 978-3-540-92673-3 (online).
9. Literatura
ALLEMANG, Dean, HENDLER, James, GANDON, Fabien. Semantic web for the working ontologist: effective modeling for linked data, RDFS and OWL. 3rd ed. New York: Association for Computing Machinery, 2020. 510 s. ACM Books 33. ISBN 978-1-4503-7617-4 (print). ISBN 978-1-4503-7615-0 (pdf). https://doi.org/10.1145/3382097. - Doprovodný web: http://workingontologist.org/.
BIAGETTI, Maria Teresa. Ontologies (as knowledge organization systems) [online]. Version 1.0. 2020-08-31, last edited 2021-10-21 [cit. 2025-04-05]. In: Encyclopedia of knowledge organization. ISKO, 2016- . Dostupné z: https://www.isko.org/cyclo/ontologies.
GÓMEZ-PÉREZ, Asunción, FERNÁNDEZ-LÓPEZ, Mariano, CORCHO, Oscar. Ontological engineering: with examples from the areas of knowledge management, e-commerce and the Semantic Web. 1st ed. London: Springer, 2004. xii, 403 s. Advanced information and knowledge processing, ISSN 1610-3947. https://doi.org/10.1007/b97353. ISBN 978-1-85233-551-9 (print). ISBN 978-1-85233-840-4 (online).
GRUBER, Thomas R. A translation approach to portable ontology specification. In: Knowledge acquisition. June 1993, 5(2), 199-220. https://doi.org/10.1006/knac.1993.1008. ISSN 1042-8143.
GRUBER, Thomas R. Ontology. In: Ling LIU, M. Tamer ÖZSU, ed. Encyclopedia of database systems. London: Springer, 2009, s. 1963-1965. https://doi.org/10.1007/978-0-387-39940-9_1318. ISBN 978-0-387-35544-3 (print). ISBN 978-0-387-39940-9 (online).
ISO/IEC 21838-1:2021. Information technology – Top-level ontologies (TLO) – Part 1: Requirements. 1st ed. Geneva: International Organization for Standardization, 2021-08 [cit. 2025-04-11]. 23 s. Dostupné z: https://standards.iso.org/ittf/PubliclyAvailableStandards/.
KUČEROVÁ, Helena. Metodiky ontologického inženýrství. In: Ikaros [online]. 2011, 15(5) [cit. 2025-04-11]. urn:nbn:cz:ik-13630. ISSN 1212-5075. Dostupné z: https://www.ikaros.cz/node/13630.
OBITKO, Marek, ZAMAZAL, Ondřej, SVÁTEK, Vojtěch. Ontologie a sémantický web. In: Vladimír MAŘÍK, Olga ŠTĚPÁNKOVÁ, Jiří LAŽANSKÝ a kol. Umělá inteligence. 6. 1. vyd. Praha: Academia, 2013, kap. 2, s. 85-125. ISBN 978-80-200-2276-9.
Ontology Summit 2021 Communiqué: Ontology generation and harmonization [online]. Ken Baclawski, Michael Bennett, Gary Berg-Cross, Leia Dickerson, Todd Schneider, Selja Seppälä, Ravi Sharma, Ram D. Sriram, Andrea Westerinen, ed. [cit. 2025-04-11]. Dostupné z: https://ontologforum.s3.amazonaws.com/OntologySummit2021/Communique/Ontology+Summit+2021+Communique.pdf.
SVÁTEK, Vojtěch, VACURA, Miroslav. Ontologické inženýrství na sémantickém webu. In: Vladimír MAŘÍK, Olga ŠTĚPÁNKOVÁ, Jiří LAŽANSKÝ a kol. Umělá inteligence. 6. 1. vyd. Praha: Academia, 2013, kap. 3, s. 149-168. ISBN 978-80-200-2276-9.
ZDRÁHAL, Zdeněk. Ontologie: od filosofie k umělé inteligenci. In: Vladimír MAŘÍK, Olga ŠTĚPÁNKOVÁ, Jiří LAŽANSKÝ a kol. Umělá inteligence. 6. 1. vyd. Praha: Academia, 2013, kap. 1, s. 21-84. ISBN 978-80-200-2276-9.